
Система o3 от OpenAI достигла уровня человека в тесте на общий интеллект. Что это значит?
Новая модель AI только что достигла результатов на уровне человека в тесте, разработанном для измерения «общего интеллекта». 20 декабря система o3 от OpenAI набрала 85% в тесте ARC-AGI, что значительно выше предыдущего лучшего результата AI в 55% и на уровне среднего результата человека. Она также показала хорошие результаты в очень сложном тесте по математике. Создание искусственного общего интеллекта, или AGI, является заявленной целью всех крупных исследовательских лабораторий AI. На первый взгляд, OpenAI, по-видимому, сделала значительный шаг к этой цели. Хотя скептицизм остается, многие исследователи и разработчики AI считают, что что-то изменилось. Для многих перспектива AGI теперь кажется более реальной, срочной и ближе, чем ожидалось.
Правы ли они? Обобщение и интеллект Чтобы понять, что означает результат o3, нужно понять, что такое тест ARC-AGI. В технических терминах, это тест на «эффективность выборки» системы AI в адаптации к чему-то новому — сколько примеров новой ситуации системе нужно увидеть, чтобы понять, как она работает. Система AI, такая как ChatGPT (GPT-4), не очень эффективна в плане выборки. Она была обучена на миллионах примеров человеческого текста, создавая вероятностные «правила» о том, какие комбинации слов наиболее вероятны. Результат довольно хорош в обычных задачах. Он плох в редких задачах, потому что у него меньше данных об этих задачах.
Пока AI-системы не смогут учиться на небольшом количестве примеров и адаптироваться с большей эффективностью выборки, они будут использоваться только для очень повторяющихся задач и задач, где допустимы редкие ошибки. Способность точно решать ранее неизвестные или новые задачи из ограниченного количества данных известна как способность обобщать. Это широко считается необходимым, даже фундаментальным, элементом интеллекта. Тест ARC-AGI проверяет адаптацию с эффективной выборкой с помощью маленьких квадратных проблем, подобных приведенной ниже. AI должен определить паттерн, который превращает сетку слева в сетку справа.
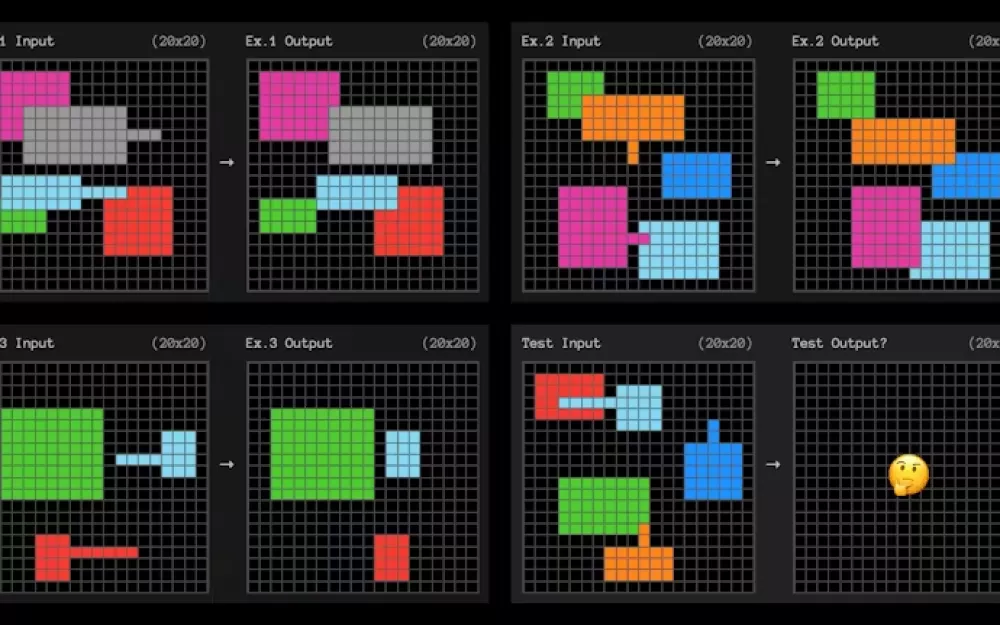
Каждый вопрос дает три примера для обучения. Система AI затем должна определить правила, которые обобщают из трех примеров к четвертому. Они очень похожи на тесты на IQ, которые вы могли помнить из школы.
Мы не знаем точно, как OpenAI это сделала, но результаты предполагают, что модель o3 очень адаптивна. Из нескольких примеров она находит правила, которые можно обобщать. Чтобы определить паттерн, мы не должны делать лишних предположений или быть более конкретными, чем это действительно необходимо. В теории, если вы можете определить «наименее сильные» правила, которые выполняют то, что вам нужно, то вы максимизировали свою способность адаптироваться к новым ситуациям.
Что мы имеем в виду под наименее сильными правилами? Техническое определение сложное, но более слабые правила обычно можно описать более простыми утверждениями. В приведенном выше примере простое выражение правила на английском языке может быть таким: «Любая форма с выступающей линией переместится в конец этой линии и 'перекроет' любые другие формы, с которыми она пересекается».Поиск цепочек мысли? Хотя мы не знаем, как OpenAI достигла этого результата, маловероятно, что они намеренно оптимизировали систему o3 для нахождения слабых правил. Однако для успешного выполнения задач ARC-AGI она должна их находить.
Мы знаем, что OpenAI начала с универсальной версии модели o3, а затем обучила ее специально для теста ARC-AGI. Французский исследователь AI Франсуа Шолле, разработавший тест, считает, что o3 ищет различные цепочки мысли, описывающие шаги для решения задачи. Затем она выбирает лучший в соответствии с каким-то слабо определенным правилом. Это было бы не слишком отличным от того, как система AlphaGo от Google искала различные возможные последовательности ходов, чтобы победить мирового чемпиона по Go. Вы можете представить эти цепочки мысли как программы, которые подходят примерам. Конечно, если это похоже на AI, играющий в го, то ему нужна эвристика, или нечеткое правило, чтобы решить, какая программа лучше.
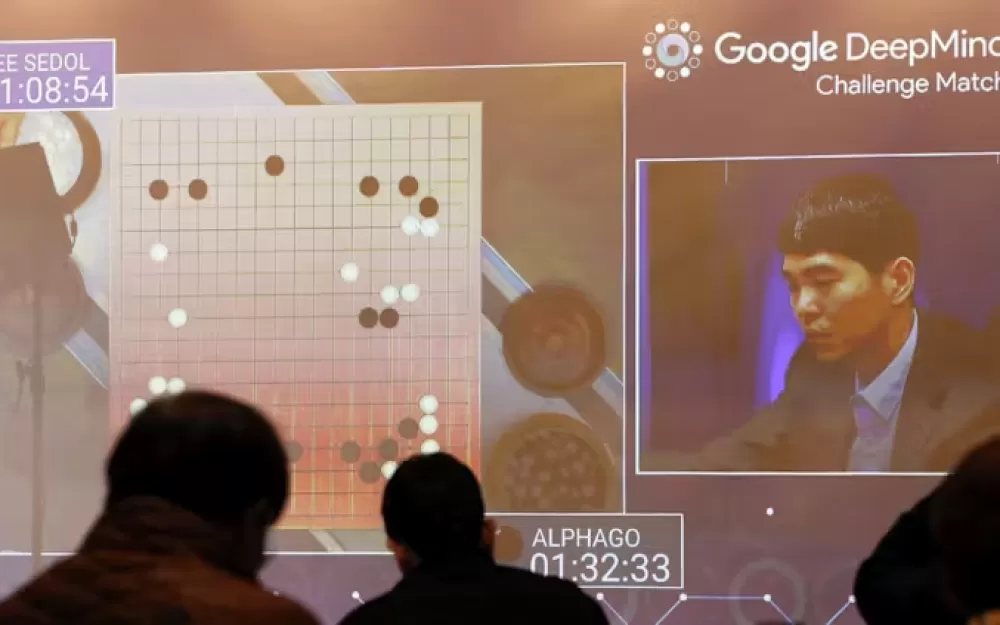
Может быть, тысячи различных, казалось бы, равнозначных программ могут быть сгенерированы. Эта эвристика может быть «выбери наименее сильную» или «выбери самую простую». Однако, если это похоже на AlphaGo, то они просто создали эвристику с помощью AI. Это был процесс для AlphaGo. Google обучил модель оценивать различные последовательности ходов как лучшие или худшие по сравнению с другими. Что мы все еще не знаем. Вопрос в том, действительно ли это ближе к AGI? Если o3 работает таким образом, тогда базовая модель может быть не намного лучше предыдущих моделей.
Концепции, которые модель изучает из языка, могут быть не более подходящими для обобщения, чем раньше. Вместо этого, мы можем просто видеть более обобщаемую «цепочку мысли», найденную через дополнительные шаги обучения эвристике, специализированной для этого теста. Доказательство, как всегда, будет в практике. Почти все о o3 остается неизвестным. OpenAI ограничила раскрытие информации несколькими медиа-презентациями и ранним тестированием для горстки исследователей, лабораторий и институтов по безопасности AI. Настоящее понимание потенциала o3 потребует обширной работы, включая оценки, понимание распределения ее возможностей, как часто она терпит неудачи и как часто добивается успеха. Когда o3 наконец будет выпущена, мы получим гораздо лучшее представление о том, действительно ли она приблизительно так же адаптивна, как средний человек. Если это так, то это может иметь огромное, революционное экономическое воздействие, открывая новую эру самоулучшающегося ускоренного интеллекта. Нам потребуются новые тесты для самого AGI и серьезное рассмотрение того, как его следует управлять. Если нет, то это все равно будет впечатляющим результатом. Однако повседневная жизнь останется в основном прежней.
Источник













Написать комментарий