
Как жить с Highload?
Как понять, применим ли для вас термин «Highload», что с этим делать и какие инструменты must have для успешного существования в высоконагруженном режиме. Разбираем на примере кейса ТЦР.
Highload — это сколько?
Highload — уже не очень новое, но все еще очень модное слово в ИТ-мире. Хотя термин применим, конечно, не только в разрезе информационных, но и к системам вообще. К примеру, Т-Банк, как организация, обслуживающая 49 млн клиентов - очень даже highload. Или нет?
Самый простой и распространенный ответ, который можно найти на просторах интернета: highload-система – система, обрабатывающая большое количество запросов в единицу времени». Но сразу вспоминается известный рекламный слоган: «Сколько вешать в граммах?». Скажем, 100 запросов в секунду это много? Конечно, нет — любой современный сервер с такой нагрузкой справится, скажете вы. И будете правы. В особенности, если ваш сервис подобен калькулятору - приняли два значения, сложили и вернули результат. А если ваша система занимается кодированием видео, то, вероятно, вы столкнулись с трудностями уже на более раннем этапе. Все запросы разные, их специфика накладывает ограничения.
Вернемся к нашему «калькулятору». Он популярен, вы добавляете новые функции, нагрузка растет, и вот уже появляются «ошибки 50Х». Вы можете поставить еще один сервер, настроить Round robin DNS, и - вуаля – производительность удвоится. Но очень вероятно, что бизнес укажет на высокую себестоимость подобного решения. Что же, тяжело вздыхаем, реализуем логирование, анализируем запросы и понимаем, что большинство запросов повторяются. Реализуем кеширование, и вот мы снова «на коне». До тех пор, пока не упремся в очередное ограничение. И тогда появятся микросервисы, балансировщики, очереди и все прочие прелести.
Вообще, бизнес очень часто накладывает ограничения. Например, контактный центр Т-Банка: он обрабатывает более 1 млн обращений в сутки и должен делать это качественно и эффективно. Для контроля качества можно было бы нанять тысячи контроллеров, которые прослушивали бы звонки, но это, как минимум, очень дорого. Поэтому в архитектуре контактного центра появился сервис речевой аналитики, который автоматически анализирует коммуникации и рассказывает операторам об их сильных и слабых сторонах.
Не существует ни методики, ни чисел для того, чтобы понять, является ли ваша система высоконагруженной. Highload — это состояние. Состояние инфраструктуры, системы, профиля нагрузки, когда вы сталкиваетесь с ограничениями и вынуждены что-то менять, добавлять вычислительных ресурсов, менять архитектуру решения. Главное — не дожидаться, когда все рухнет.
Надежность
Любая система рано или поздно рухнет. Но высоконагруженная система сделает это с большей вероятностью, а ее восстановление будет долгим и сложным. В 2022 году консалтинговая компания Information Technology Intelligence Consulting (ITIC) обнародовала подсчеты: за 1 час простоя компании в среднем теряют $300 тыс. И это понятно: ведь системы нагружаются не сами по себе, ими пользуются, и много, то есть их ценность велика.
Бен Трейнор Слосс (Ben Treynor Sloss), вице-президент по инженерным практикам Google, как-то сказал: «Надежность - это главная характеристика продукта, так как система, которой невозможно пользоваться, бесполезна». Но почему-то при составлении технического задания на системы об этом забывают. Хотя мы в Т-Банке считаем, что это должно быть пререквизитом к техзаданию на любую систему.
Надежность, являясь обязательным атрибутом качества вашего продукта, объединяет в себе доступность, производительность и непрерывность:
Доступность — время, когда пользователи могут воспользоваться вашим сервисом. Например, клиенты могут зайти на ваш веб-сайт, прочитать новости, посмотреть товары.
Производительность — скорость работы вашего сервиса. Если из-за наплыва пользователей или запуска какой-либо процедуры - например, создания отчета - страницы грузятся медленно, клиенты уйдут к конкуренту. В исследовании Amazon говорится о том, что каждые 100мс загрузки страницы снижают конверсию сайта на 7%, выручку на 1%.
Непрерывность означает, что каждый раз, проделывая ту же операцию, пользователь получает тот же результат. Если ваш «калькулятор» в час наибольшей нагрузки будет выдавать 5 на 2+2, или не отображать список заказов, то надежными вас не назовут.
Помимо надежности, при разработке архитектуры высоконагруженной системы необходимо учитывать ее управляемость — то, насколько просто будет масштабировать систему, выявлять «бутылочные горлышки» и причины отказов. А еще потребление, то есть расходы на ресурсы (количествоо CPU, RAM, пропускная способность сети и т.д.), лицензии на стороннее ПО, если таковое используется, и фонд оплаты труда команды эксплуатации.
Архитектура — это основа системы. Аналогично строительству: качество здания зависит от того, насколько прочен фундамент. Устойчивость системы будет зависеть от архитектуры. Но разработать грамотную архитектуру — надежную, управляемую и эффективную — мало. Не бывает плохих или хороших архитектур - бывают подходящие и неподходящие. Но любая архитектура сервиса без связанного с ним мониторинга, который будет способен отслеживать работу компонентов, производительность, нагрузку, а также качество с точки зрения пользователей и влияние на бизнес-результаты, будет неподходящей. Внедрение подсистемы метрик, мониторинга и логирования как инструментов диагностики ошибок и причин сбоев — must have.
Стоимость системы наблюдаемости может быть велика, измеряться десятками процентов от стоимости реализации проекта в целом. Часто компании игнорируют эти затраты, считают, что незачем вкладывать серьезные средства в функционал, который, по их мнению, не приносит прибыли. И часто это становится ошибкой, которая сильно бьет по компании, принося не только тысячи долларов убытка за минуту сбоя, и даже может стать причиной банкротства. Кейсов немало. Например, в 2012 году Knight Capital Group за 40 минут сбоя потеряла $465 млн и прекратила существование.
Но даже если вас минует сия чаша, игнорирование вопроса о системе мониторинга рано или поздно приведет к проблемам. Развивать решение будет все сложнее, так как вы не понимаете, как оно работает, где и почему формируются «бутылочные горлышки», какова первопричина того или иного инцидента, и как инциденты влияют на бизнес в целом. Вам будет не хватать данных в целом. Классический подход к аналитике данных включает проектирование тех или иных метрик, их накопление и визуализацию в BI. Каждый такой цикл может длиться месяцы, результаты вы получаете с задержкой в часы, а иногда и сутки. Но если та или иная гипотеза не срабатывает, вы вынуждены повторить его. При этом данные телеметрии, которыми оперируют, так или иначе, все системы мониторинга, представляют собой самую подробную информацию о том, что происходит в компании. И эти данные представляют огромную ценность.

Наблюдаемость как новый уровень мониторинга
В департаменте базовых технологий Т-банка, где я работаю, мы разрабатываем платформы, на базе которых строятся и функционируют все остальные системы и сервисы. Одно из таких решений — платформа наблюдаемости Sage Observability. Наблюдаемость считается развитием мониторинга. Но я бы сказал, что наблюдаемость выводит мониторинг на новый уровень — она дает возможность не только отслеживать те или иные параметры, но дает комплексное понимание того, как работает компания в целом, включая инфраструктуру, приложения, бизнес-процессы.
Sage Observability
Sage позволяет агрегировать логи, события, метрики, маршруты запросов (трассировки). Реальное время доставки данных позволяет настроить мониторинг на любом уровне — следить не только за параметрами процессора, объема памяти или свободного места на диске, но и показывать связность компонентов, выявлять узкие места, анализировать архитектуру. А также рассчитывать бизнес-метрики, визуализировать и уведомлять ответственных, если что-то пошло не так с точки зрения логики сервисов.
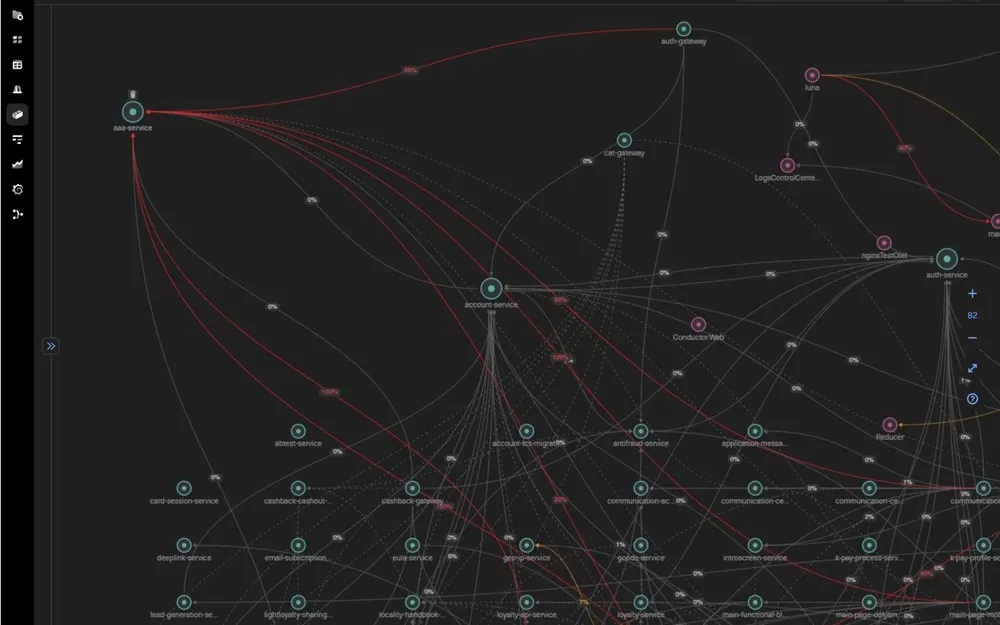
Как результат - сквозное понимание того, как работает система от запросов пользователей до «железа». Важный параметр в кредитовании — уровень подтверждения заявки. Проще говоря, соотношение количества поступивших заявок к одобренным. Скоринговые модели сложны, и любая ошибка в формуле может привести либо к недополученной прибыли (одобрили слишком мало), либо к убыткам (одобрили слишком много, получили много некачественных кредитов). Благодаря Sage можно в реальном времени отслеживать такие составные параметры и сигнализировать о проблемах с логикой. С технической частью при этом все будет в порядке.
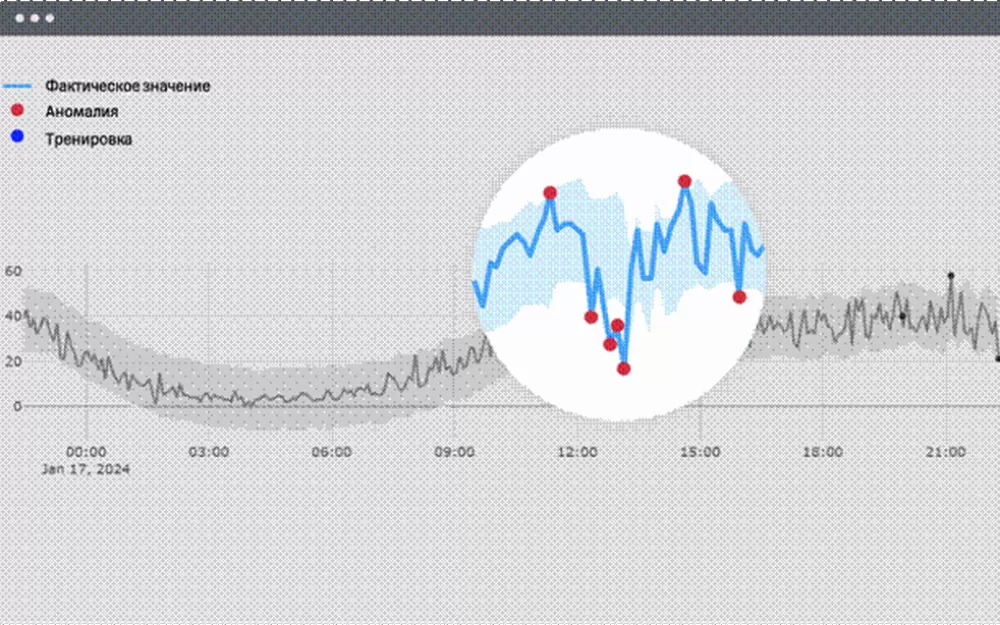
ML-алгоритмы хорошо подходят для выявления аномалий в бизнес-процессах, когда сложно или даже почти невозможно выставить пороги. Как это выглядит – показано на скриншоте Аnomaly Аnalyzer.
С внедрением Sage мы также сняли с разработчиков огромный пласт задач, связанных с аналитикой. Незачем в приложениях реализовывать аналитическую часть, когда все можно рассчитать на базе событий. Это сильно ускоряет внедрение новых функций и упрощает системы.
В Т-банке Sage является основным поставщиком данных. Эта информация может хранится длительное время и использоваться для аналитики - продуктовой, процессной. Главное, что эти данные всегда есть и находятся под рукой. Таким образом, мы можем сразу ответить на любой вопрос, даже на тот, который возникнет завтра.
Sage как пример высоконагруженной системы
Сейчас Sage Observability это одна из самых крупных систем в Т-Банке, занимающая около 10% всех вычислительных ресурсов. Его «глаза», точнее — приборная панель. Платформа обрабатывает гигабайты данных в секунду, количество триггеров, выполняемых расчеты в реальном времени — десятки тысяч. И если все прочие системы должны быть надежными, Sage должна быть супернадежной. Даже в случае возникновения массового сбоя в инфраструктуре банка, когда количество логов (событий), метрик увеличивается в разы за секунды, Sage должна работать. Это критически важное условие, ведь без него разобраться в том, что происходит, будет крайне сложно. Создать такое решение — нетривиальная задача.
Мы применяем различные архитектурные паттерны, например, N-Tier для разделения пайплайнов записи данных в хранилища. Для каждого типа данных в каждом дата-центре (Sage - кросс-кластерная, кросс-датацентровая система) строится свой процесс приема данных. А еще Batch Processing, Queue-based Load Leveling, репликацию данных внутри кластеров и многие другие — все для того, чтобы система работала в режиме High Availability на любых нагрузках, помогая обеспечивать быстрое устранение даже сложных сбоев. Причем не только в Т-Банке, но и в макро-масштабах. В частности, НСПК (оператор платежной системы «Мир» и Системы быстрых платежей) также использует платформу Sage Observability для обеспечения надежности.













Написать комментарий