
Тест BIG-Bench Extra Hard: как он выявляет недостатки в больших языковых моделях
В 2021 году был создан BIG-Bench — универсальный инструмент для тестирования больших языковых моделей. Однако с развитием технологий современные модели стали обеспечивать точность более 90%, и BIG-Bench достиг своего предела. В ответ на это Google DeepMind разработала тест BIG-Bench Extra Hard , который позволяет выявлять существенные недостатки даже в самых передовых моделях ИИ.
BBEH — это усовершенствованная версия BIG-Bench Hard (BBH). В BBEH каждое из 23 заданий, которые были в BBH, стало сложнее. Новые задания требуют от участников более широкого спектра логических навыков. Они также в среднем в шесть раз длиннее, чем задания BBH. Повышенная сложность заданий отражается в ответах моделей ИИ. Они обычно в семь раз длиннее, чем ответы BBH.
В новом тесте предстоит продемонстрировать умение мыслить логически, в том числе способность анализировать и делать выводы в условиях сложных логических связей, осваивать новые идеи, отделять важную информацию от второстепенной и находить ошибки в логических цепочках.
Два примера показывают, насколько непрост этот тест. В задании на пространственное мышление агент перемещается по геометрической структуре и наблюдает за объектами в разных точках. Модели должны отслеживать положение объектов и делать выводы об их взаимосвязях.
В задании «Свойства предметов» предлагается набор предметов с разнообразными параметрами: цветом, габаритами, происхождением, ароматом и материалом. Эти параметры могут меняться. Модели должны внимательно следить за изменениями характеристик всех предметов, в том числе в сложных ситуациях, например, когда теряется предмет с определёнными свойствами.
Google DeepMind протестировал как универсальные модели, такие как Gemini 2.0 Flash и GPT-4o, так и специализированные модели для логических рассуждений, такие как o3-mini (high) и DeepSeek R1. Результаты выявили значительные ограничения: лучшая универсальная модель (Gemini 2.0 Flash) показала среднюю точность в 9,8%, а лучшая модель для логических рассуждений (o3-mini high) показала средний результат в 44,8%. GPT-4.5 ещё не тестировался.
Исследование показало, что существуют ожидаемые различия между общими и специализированными моделями логический рассуждений. Специализированные модели особенно хорошо справлялись с формальными задачами, связанными со счётом, планированием, арифметикой и структурами данных. Однако их преимущество уменьшалось или исчезало при выполнении задач, требующих здравого смысла, чувства юмора, сарказма и понимания причинно-следственных связей.
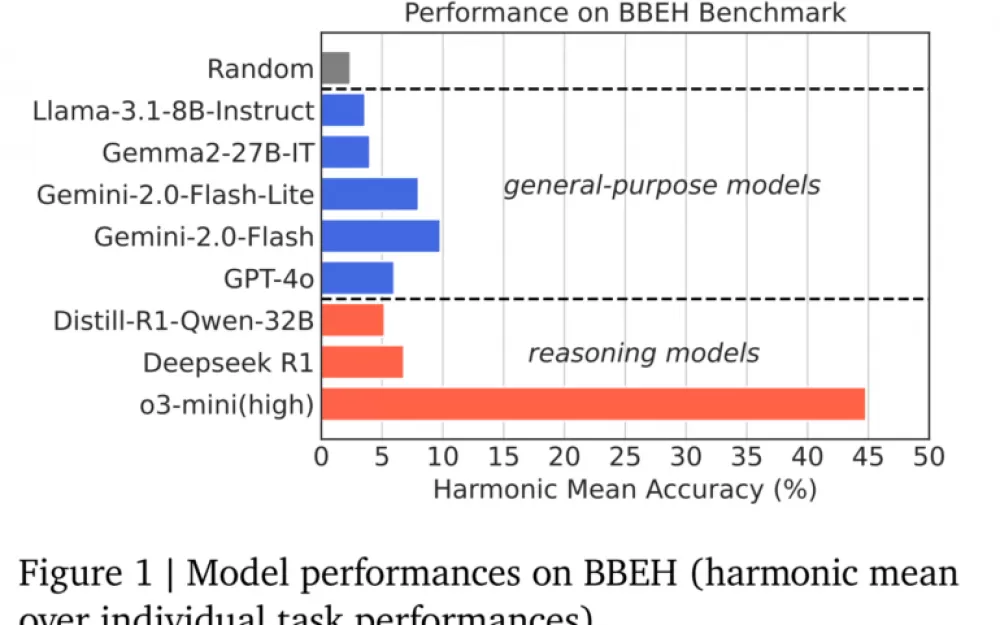
Примечательно, что o3-mini (high) от OpenAI значительно превзошел широко обсуждаемый DeepSeek R1. Китайская модель не справилась с несколькими тестами, включая полный провал теста «Свойства предмета». Исследователи объясняют это главным образом тем, что модель сбивается с пути, когда не может решить проблему с эффективной длиной выходного токена. Средняя точность R1 составила всего 6,8%, что на три процента ниже, чем у Gemini 2.0 Flash.
Исследование показало, что специализированные модели рассуждений получают больше преимуществ перед общими моделями по мере увеличения длины контекста и сложности мышления. Аналогичным образом, более крупные общие модели, такие как Gemini 2.0 Flash, демонстрируют преимущества перед более мелкими моделями, такими как Flash-Lite, при работе с более длинными контекстами.
В то время как современные LLM добились значительного прогресса, BBEH демонстрирует, что они по-прежнему далеки от достижения общей способности рассуждать. Исследователи подчеркивают, что все еще необходимо приложить много усилий для устранения этих пробелов и разработки более универсальных систем ИИ.
Источник












Написать комментарий