
Помощники AI не прошли базовую проверку фактов в исследовании BBC News
Систематическая оценка ведущих чат-ботов на основе искусственного интеллекта выявляет широко распространенные проблемы с точностью и надежностью при обработке новостного контента. В ходе исследования, проведенного BBC , проверялась способность ChatGPT, Microsoft Copilot, Google Gemini и Perplexity точно сообщать о текущих событиях.
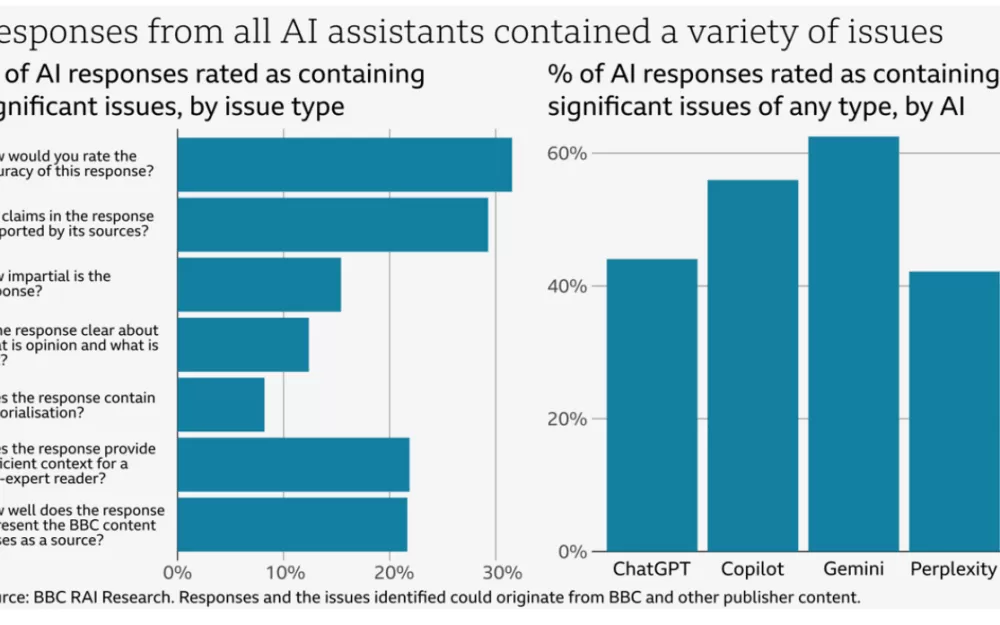
В декабре 2024 года 45 журналистов BBC оценили, как эти системы AI обрабатывают 100 текущих новостных вопросов. Они оценивали ответы по семи ключевым областям: точность, указание источника, беспристрастность, разделение фактов и мнений, комментарии, контекст и правильная обработка контента BBC. Каждый ответ оценивался по шкале от «нет проблем» до «существенные проблемы».
51 процент ответов AI содержал существенные проблемы, начиная от элементарных фактических ошибок до полностью сфабрикованной информации. Когда системы специально цитировали контент BBC, 19 процентов ответов содержали ошибки, а 13 процентов содержали либо сфабрикованные, либо неверно приписанные цитаты.
Некоторые из ошибок могут иметь реальные последствия. Google Gemini ошибочно утверждал, что Национальная служба здравоохранения Великобритании (NHS) не рекомендует парить, хотя на самом деле орган здравоохранения рекомендует электронные сигареты, чтобы помочь людям бросить курить. Perplexity AI сфабриковал подробности о смерти научного журналиста Майкла Мосли, а ChatGPT не признал смерть лидера ХАМАС, назвав его действующим лидером спустя несколько месяцев после его смерти.
Помощники AI регулярно цитировали устаревшую информацию как текущие новости, не отделяли мнения от фактов и упускали важный контекст из своих отчетов. Например, Microsoft Copilot представил статью 2022 года о независимости Шотландии так, как будто это были текущие новости.
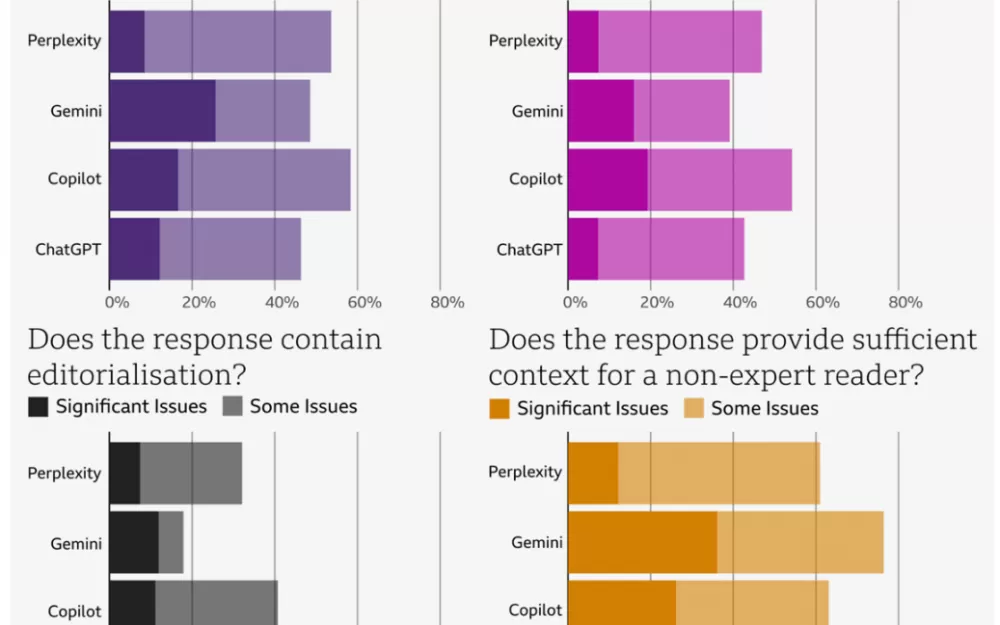
BBC установила высокую планку в своей оценке — даже небольшие ошибки считались «значительными проблемами», если они могли ввести в заблуждение того, кто читает ответ. И хотя стандарты были жесткими, проблемы, которые они обнаружили, соответствовали тому, что уже видели другие исследователи о том , как ИИ спотыкается при обработке новостей.
Возьмем один из наиболее ярких примеров: чат-бот Bing от Microsoft настолько запутался, читая судебные репортажи, что обвинил журналиста в совершении тех самых преступлений, о которых он сообщал.
BBC заявляет, что в ближайшем будущем снова проведет это исследование. Привлечение независимых рецензентов и сравнение того, как часто люди совершают схожие ошибки, может сделать будущие исследования еще более полезными — это поможет показать, насколько велик разрыв между производительностью человека и AI.
BBC признает, что их исследование, хотя и раскрывает, только начинает раскрывать весь масштаб проблемы. Задача отслеживания этих ошибок сложна. «Масштаб и объем ошибок и искажения достоверного контента неизвестны», — говорится в отчете BBC.
Помощники AI могут давать ответы на практически неограниченный круг вопросов, и разные пользователи могут получать совершенно разные ответы, задавая один и тот же вопрос. Эта непоследовательность делает систематическую оценку крайне сложной.
Проблема выходит за рамки пользователей и журналистов. Медиакомпании и регуляторы не имеют инструментов для полного мониторинга или измерения этих искажений. Возможно, самое тревожное, что BBC предполагает, что даже сами компании AI могут не знать истинных масштабов ошибок своих систем.
«Регулирование может сыграть ключевую роль в обеспечении здоровой информационной экосистемы в эпоху искусственного интеллекта», — пишет BBC.
Источник













Написать комментарий