
Deepseek v3 на уровне o1 OpenAI: что показывают независимые бенчмарки
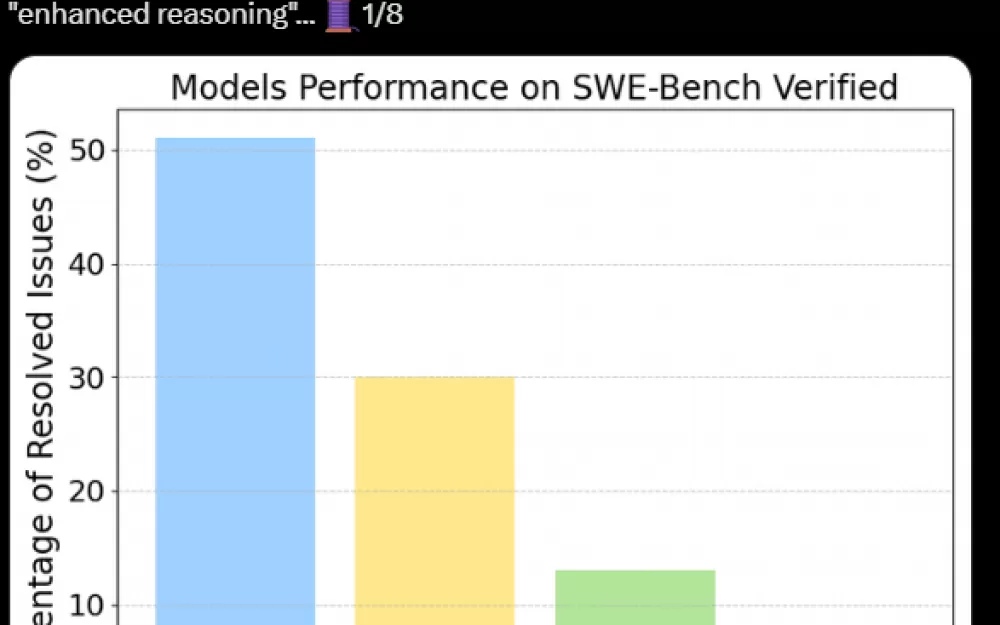
Независимые тесты показали, что модель o1 от OpenAI решает лишь 30 процентов программных задач в бенчмарках, а не 48,9 процента, как утверждала компания. Эти результаты добавляют масла в огонь растущей дискуссии о том, как измерять возможности AI.
В своем новом исследовании, используя кодировочный бенчмарк OpenAI "SWE-Bench Verified", исследователь AI Александро Квадрон обнаружил то, что он называет удивительным разрывом. В то время как OpenAI сообщала, что их модель справляется почти с половиной реальных программных задач с GitHub, тестирование Квадрона показывает, что она решает менее трети задач.
Sonnet 3.5 от Anthropic обошел конкурентов, решив 53 процента задач — возможно, потому что модель помогала разрабатывать саму процедуру тестирования. Примечательно, что менее дорогая модель Deepseek v3 показала результаты примерно на уровне o1 от OpenAI в тестах Квадрона.
Почему такое большое различие? Разрыв между заявлениями OpenAI и выводами Квадрона объясняется методами тестирования. OpenAI использовала "Agentless" — фреймворк, предоставляющий AI очень конкретные инструкции для решения программных задач. Квадрон, с другой стороны, использовал "OpenHands", который дает AI больше свободы в подходе к решению проблем.
Квадрон утверждает, что OpenHands считался золотым стандартом, когда OpenAI проводила свои тесты, но они решили его не использовать. Он подозревает, что более жесткий метод тестирования OpenAI может отдавать предпочтение моделям, которые просто запоминают решения, вместо того чтобы действительно решать новые проблемы независимо.
Это не просто академическая придирка. OpenAI подчеркивала якобы сильные стороны o1 в области рассуждений и способности справляться с новыми задачами. "Но почему o1 испытывает трудности с истинным открытым планированием, несмотря на свои возможности рассуждений?" — пишет Квадрон.
Другие исследования уже сомневались в этих заявлениях. Недавний бенчмарк по планированию путешествий показал, что o1-preview испытывает трудности с задачами планирования, а исследование Apple обнаружило, что даже незначительные изменения в математических задачах приводили к гораздо худшим результатам — что указывает на то, что модель плохо обобщает знания, что подрывает утверждения о ее логических способностях.
Эта ситуация подчеркивает постоянную проблему оценки AI: результаты бенчмарков сильно зависят от методов тестирования. Когда компании могут оптимизировать свои модели под конкретные процедуры тестирования, становится практически невозможно для внешних наблюдателей оценить истинные возможности AI. Это важно, потому что результаты бенчмарков ведут PR-кампании и маркетинговые усилия, которые, в свою очередь, влияют на финансирование со стороны инвесторов.
Логан Килпатрик, недавно перешедший из OpenAI на должность руководителя продукта в Google AI Studio, подчеркивает необходимость лучшей верификации и открытости в процедурах тестирования. Хотя он не подозревает OpenAI в какой-либо преднамеренной обмане, он считает, что решение этих проблем оценки критически важно для разработки более продвинутых систем AI.
Источник













Написать комментарий