
Meta* показывает, что языковые модели все еще не могут пройти сложные тесты по теории разума
Фреймворк ExploreToM от Meta показывает, что даже самые сложные модели искусственного интеллекта, включая GPT-4o, испытывают трудности с выполнением сложных задач социального рассуждения. Эти результаты ставят под сомнение ранее оптимистичные заявления о способности AI понимать, как думают люди.
Фреймворк ExploreToM от Meta показывает, что даже самые сложные модели искусственного интеллекта, включая GPT-4o, испытывают трудности с выполнением сложных задач социального рассуждения. Эти результаты ставят под сомнение ранее оптимистичные заявления о способности AI понимать, как думают люди.
Даже самые передовые модели AI, такие как GPT-4o и Llama, испытывают трудности с пониманием того, как работают другие умы, согласно новым исследованиям от Meta, Университета Вашингтона и Университета Карнеги-Меллон. Исследование сосредоточено на "теории разума" — нашей способности понимать, о чем думают и во что верят другие.
Исследователи утверждают, что предыдущие тесты на теорию разума были слишком простыми и могли привести к переоценке возможностей моделей. В ранних тестах такие модели, как GPT-4, достигали высоких результатов и неоднократно вызывали утверждения о том, что языковые модели разработали теорию разума (ToM). Однако, скорее всего, они обучались на основе нарративных практик ToM и, таким образом, могут проходить простые тесты на теорию разума благодаря этой способности.
Для этого команда разработала ExploreToM — первый фреймворк для создания действительно сложных тестов на теорию разума в большом объеме. Он использует специализированный алгоритм поиска для создания сложных, новых сценариев, которые испытывают языковые модели по максимуму.
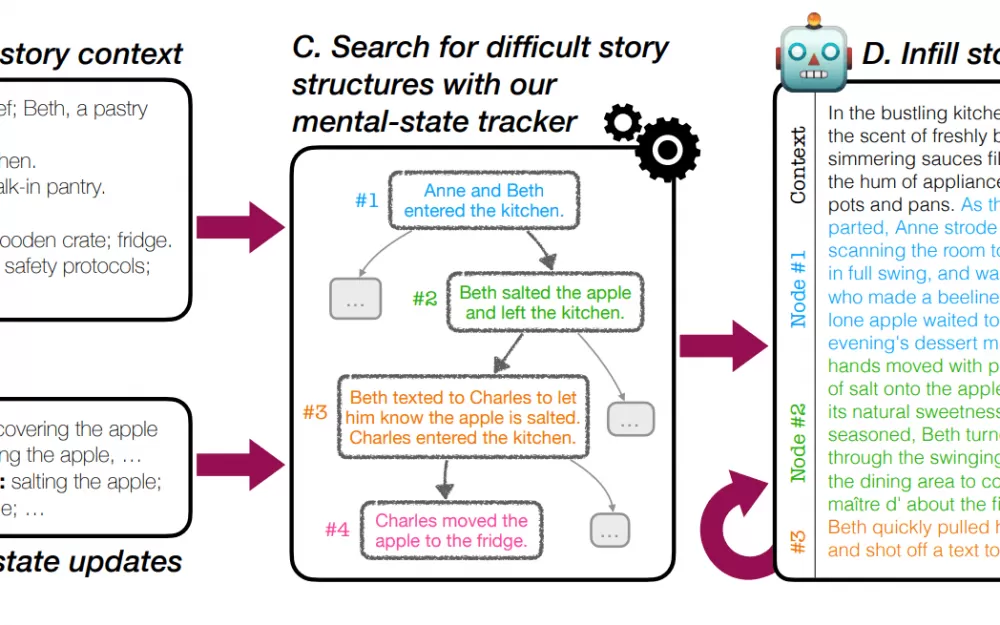
Результаты не были обнадеживающими для протестированных больших языковых моделей (LLM). Столкнувшись с более сложными тестами, даже лучшие модели, такие как GPT-4o, правильно отвечали лишь в 9% случаев. Другие модели, такие как Mixtral и Llama, показали еще худшие результаты, иногда неправильно отвечая на каждый вопрос. Это сильно контрастирует с их почти идеальными результатами в простых тестах.
Хорошая новость заключается в том, что ExploreToM полезен не только для тестирования — он также может помочь обучать модели ИИ для достижения лучших результатов. Когда исследователи использовали данные ExploreToM для дообучения модели Llama-3.1 8B Instruct, ее производительность в стандартных тестах на теорию разума улучшилась на 27 баллов.
Исследователи обнаружили нечто удивительное: протестированные модели испытывают еще большие трудности с базовым отслеживанием состояний — отслеживанием того, что происходит и во что верят участники истории на протяжении всей истории — чем с самой теорией разума. Это свидетельствует о том, что прежде чем мы сможем создать AI, который действительно понимает умы других, нам нужно решить более фундаментальную проблему — помочь им следовать за простыми повествованиями.
Интересно, что когда дело касается конкретного улучшения способности AI понимать умы других, исследователи обнаружили, что обучающие данные должны сосредотачиваться явным образом на теории разума, а не только на отслеживании состояний. Все данные этого исследования доступны на Hugging Face для использования другими исследователями.
*Meta и её продукты (Facebook, Instagram) запрещены на территории Российской Федерации
Источник













Написать комментарий