
Answer.AI и LightOn представляют ModernBERT: Новая веха в NLP
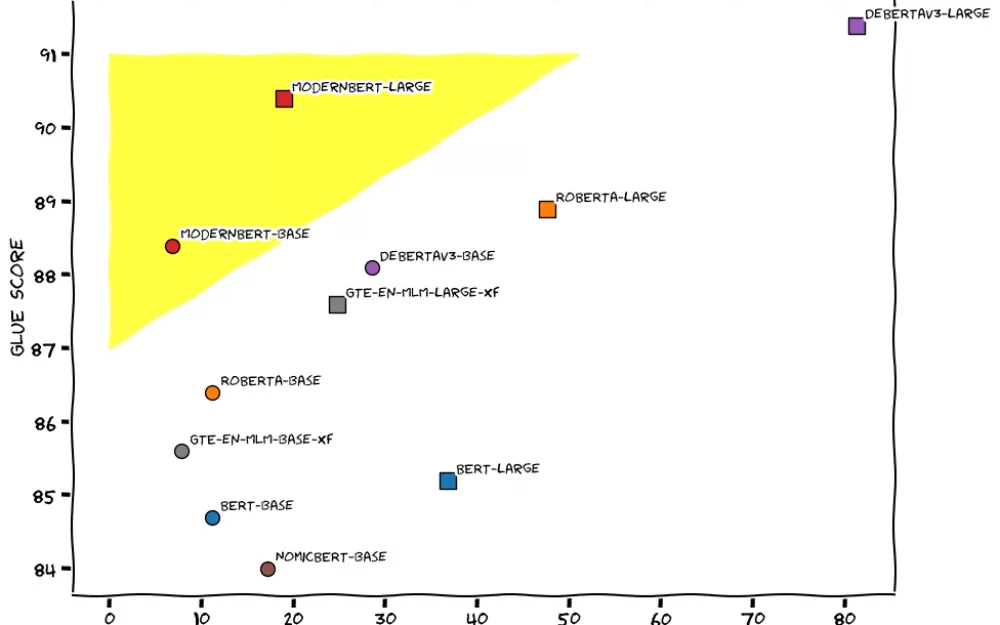
Answer.AI и LightOn объявили о выпуске ModernBERT, новой модели обработки естественного языка с открытым исходным кодом, которая превосходит BERT от Google по скорости, эффективности и качеству. Согласно сообщению в блоге разработчиков, эта модель, работающая только с энкодером, обрабатывает текст в четыре раза быстрее своего предшественника, используя при этом меньше памяти. Команда обучила ModernBERT на 2 триллионах токенов из веб-документов, программного кода и научных статей.
ModernBERT может работать с текстами длиной до 8192 токенов, что в 16 раз больше типичного предела в 512 токенов для существующих моделей-энкодеров. Это также первая модель энкодера, обученная на программном коде. Модель набрала более 80 баллов на наборе данных вопросов и ответов StackOverflow, установив рекорд для моделей, использующих только энкодер.
Разработчики сравнивают ModernBERT с Honda Civic, настроенной для гоночной трассы: «Когда вы выезжаете на шоссе, вы обычно не меняете свою машину на гоночный автомобиль, а надеетесь, что ваше повседневное надежное средство передвижения сможет комфортно достичь скоростного лимита». Значительное снижение затрат на обработку текста в крупном масштабе.
В то время как крупные языковые модели, такие как GPT-4, стоят несколько центов за запрос и требуют секунд на ответ, ModernBERT работает локально и гораздо быстрее и дешевле, по словам разработчиков. Например, фильтрация 15 триллионов токенов в проекте FineWeb Edu обошлась в $60,000 с использованием модели на базе BERT. Та же задача стоила бы более $1 миллиона даже с Google Gemini Flash, самым дешевым вариантом на основе декодера.
Разработчики утверждают, что ModernBERT подходит для многих реальных приложений, от систем генерации с дополнением поиска (RAG) до поиска кода и модерации контента. В отличие от GPT-4, которая требует специализированного оборудования, модель эффективно работает на потребительских игровых GPU. ModernBERT доступен в двух версиях: базовая модель с 139 миллионами параметров и большая версия с 395 миллионами параметров. Обе модели теперь доступны на Hugging Face с лицензией Apache 2.0 и пользователи могут заменить ими свои текущие модели BERT. Команда планирует выпустить более крупную версию в следующем году, но не имеет планов по добавлению мультимодальных возможностей.
Чтобы стимулировать разработку новых приложений, разработчики запустили конкурс, в рамках которого будут вручены $100 и шестимесячная подписка Hugging Face Pro каждому из пяти лучших демо. Google представила BERT (Bidirectional Encoder Representations from Transformers) в 2018 году, используя его в основном для поиска Google. Модель остается одной из самых популярных на HuggingFace, с более чем 68 миллионами загрузок в месяц.
Источник













Написать комментарий