
Hugging Face выпустила SmolTalk — синтетический датасет для обучения языковых моделей
Разработчики платформы Hugging Face представили SmolTalk — синтетический англоязычный датасет для обучения больших языковых моделей. Он включает в себя существующие и новые наборы данных. С его помощью Hugging Face обучала нейросеть SmolLM2.
Датасет состоит почти из 2,2 млн строк данных, а его размер составляет более 4 ГБ. Разработчики заметили, что языковые модели, обученные на открытых данных, оказываются менее эффективными, если сравнивать их с нейросетями на основе проприетарных датасетов. Поэтому команда Hugging Face собрала коллекцию из нескольких открытых датасетов и дополнительно сгенерировала дополнительные наборы. Это поможет языковым моделям лучше справляться с задачами перефразирования, редактирования и пересказа текстов.
В SmolTalk входят следующие датасеты:
Smol-Magpie-Ultra (новый);
Smol-contraints (новый);
Smol-rewrite (новый);
Smol-summarize (новый);
OpenHermes2.5;
MetaMathQA;
NuminaMath-CoT;
Self-Oss-Starcoder2-Instruct;
Читайте так же:SystemChats2.0;
LongAlign-10k;
Everyday-conversations;
APIGen-Function-Calling;
Explore-Instruct-Rewriting.
Дополнительные синтетические данные сгенерировали с помощью фреймворка Distilabel. Эти датасеты доступны по лицензии Apache 2.0, а остальные наборы распространяются по правилам, которые установили их разработчики.
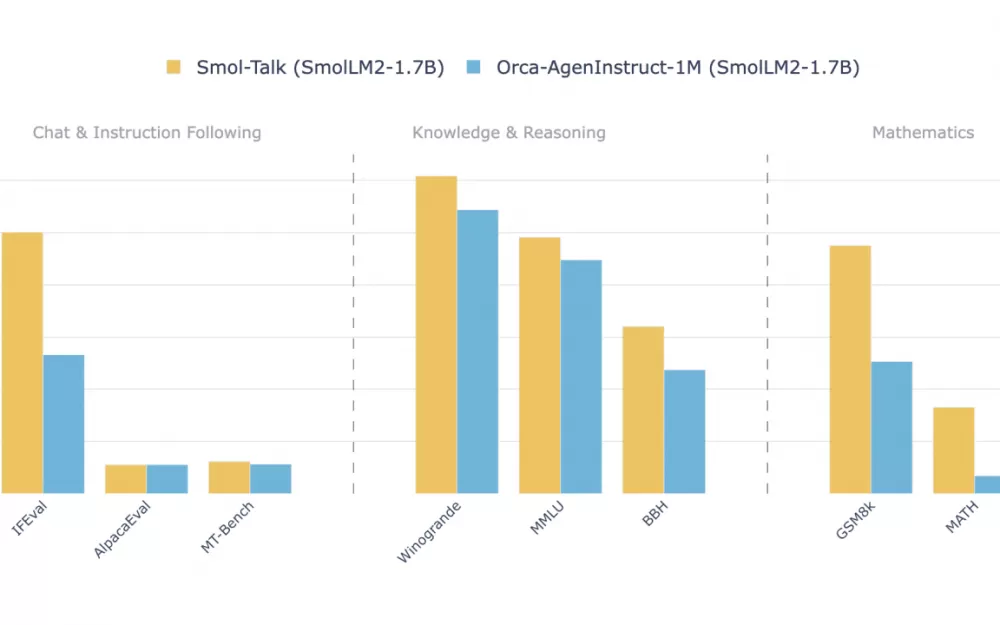
Разработчики сравнили языковые модели, обученные на SmolTalk и Orca AgentInstruct 1M от Microsoft. Нейросеть на базе данных от Hugging Face показала лучшие результаты.













Написать комментарий