
Отчёт: мнение компаний непропорционально сильно влияет на то, как СМИ пишут про ИИ
Некоммерческая организация Computer Says Maybe провела анализ 90 статей газеты New York Times, чтобы выявить, как про искусственный интеллект пишут современные средства массовой информации. Как утверждает отчёт об этом исследовании, непропорционально большу́ю роль в новостном нарративе играют компании сферы ИИ.
Доходит до того, что людей уровня Илона Маска и Сэма Альтмана называют экспертами, а специалисты из научной среды и правозащитных организаций в статьях описаны как сторонние эксперты, критики или скептики. При этом первая группа упоминается в разы чаще.
Бум генеративного искусственного интеллекта последних лет привёл к появлению многомиллиардных стартапов, росту капитализации связанных с ними компаний и общим фундаментальным сдвигам в индустрии. Про ИИ много пишут учёные, журналисты и законодатели, определяя отношение к технологии общества.
Полноценные попытки проанализировать тон этих сообщений уже бывали. Научная статья «The news framing of artificial intelligence: a critical exploration of how media discourses make sense of automation» (doi:10.1007/s00146-022-01511-1) попыталась оценить СМИ ещё в июне 2022 года, за месяцы до открытия сервиса ChatGPT и релиза Stable Diffusion 1.0. Уже тогда методы автоматизированного анализа выявили, что сообщения про ИИ вышли из рамок нишевых сводок индустрии в общую новостную повестку.
Такой анализ публикуется не только в научных изданиях. К примеру, некоммерческая организация Rootcause летом 2023 года проанализировала размах обсуждений искусственного интеллекта в Интернете и опубликовала свой отчёт. В прицел исследования попали 30 тыс. видеороликов на YouTube и тысяча статей в СМИ; также были задействованы интервью с 10 экспертами сферы ИИ. Rootcause выявила и описала основные фреймы медиасообщений. Отчёт также оценил популярность 20 организаций сферы ИИ. Оказалось, что тройка известных компаний отрасли — OpenAI, Google и Microsoft — доминирует в любых обсуждениях, обходя сумму влияния следующих 17 строчек.
В начале июля этого года свой отчёт с анализом СМИ и искусственного интеллекта представила Computer Says Maybe, действующая в общественных интересах фирма [public interest firm]. Автором 26-страничного документа указана аналитик-исследователь Ханна Баракат.
Исследование касалось не разнообразных печатных изданий и не огромного числа видеороликов. Как следует из названия отчёта «Selective Perspectives: A Content Analysis of The New York Times’ Reporting on Artificial Intelligence», анализу подвергли только статьи из газеты New York Times. Отчёт обосновывает подобное тем, что NYT — одно из важнейших изданий в США, которое к тому же позиционирует себя лидером вопросов использования ИИ в журналистике. В декабре 2023 года газета даже рассказала о своих инициативах в этом направлении.
В анализ попали статьи NYT с упоминанием слов «artificial intelligence», опубликованные с 1 января 2024 года по 31 марта 2024 года. Таковых оказалось 593. Чтобы сузить поиск, из этих статей отобрали только те, которые размещались в разделе «Технологии», чтобы не фокусироваться на тематике бизнеса, политики и культуры. Так в датасете осталось 90 статей.
Если вспомнить эти три месяца, то новостную повестку определяло судебное разбирательство газеты New York Times против OpenAI и Microsoft, планы Reddit по первичному публичному размещению на бирже (пять статей из датасета) и автоматизация с помощью ИИ некоторых операций внутри самой NYT. Также заметную роль играли массовые увольнения в индустрии высоких технологий и конференции по типу Nvidia GTC 2024.
Отчёт жалуется, что недавно газета New York Times закрыла свой API, чтобы обрубить компаниям ещё один бесплатный источник для датасетов обучения моделей. Поэтому тексты статей пришлось скрейпить с помощью скрипта на Python с использованием сервиса Octoparse.
Собственно анализ проводился опять же с помощью скриптов на Python. Их простота варьировалась в зависимости от задачи. Например, выявление частоты цитирования и числа упоминаний — это тривиальный подсчёт названий организаций и имён людей. Впрочем, даже на этом этапе пришлось вручную чистить данные, поскольку некоторые компании названы именем основателя: фонд венчурных инвестиций Andreessen Horwitz, юридическая фирма Susman Godfre и так далее.
Вручную также добавили характеристики каждой персоны: расу, пол, профессию, должность, работодателя и так далее. Данные получали из поисковиков. Для малоизвестных личностей это срабатывало не всегда, поэтому часть значений осталась неустановленной.
Анализ данных шёл в два этапа:
На первом этапе личности распределили по сферам: технологическая организация, финансовый сектор, государство, бизнес, гражданское общество, научное сообщество, творческая сфера, журнализм и так далее.
Затем скриптом искали упоминания этих людей в предложениях, где присутствовали лингвистические индикаторы цитат (слова вида «сказал» и «утверждает»). Скрипт помог также выявить выражения для семантических прокси-слов («эксперты утверждают», «БЯМ» [большая языковая модель], «чатбот») для дальнейшего изучения.
Кроме статистических методов прикладной математики в исследование включили популярный в социальных науках анализ фрейма. В тексте 9 статей попытались выявить методы представления ИИ и задействованные метафоры: лексикон, присутствующие и опущенные факты, контекст вокруг цитат и комментарии от читателей.
Полученные результаты во многом совпали с предыдущими находками. К примеру, как и в исследовании Rootcause, у Computer Says Maybe самыми часто упоминаемыми людьми оказались признанные эксперты отрасли по типу Альтмана, Маска и Кука.
В 90 статьях NYT чаще всего упоминались OpenAI (410 раз), Google (346), Microsoft (246), Apple (187), Meta (136), Amazon (102), Anthropic (85) и сама New York Times (59). Nvidia, производителя видеоускорителей, популярных для запуска генеративных моделей, упомянули всего 45 раз. У Figma и X/Twitter было по 41 упоминанию.
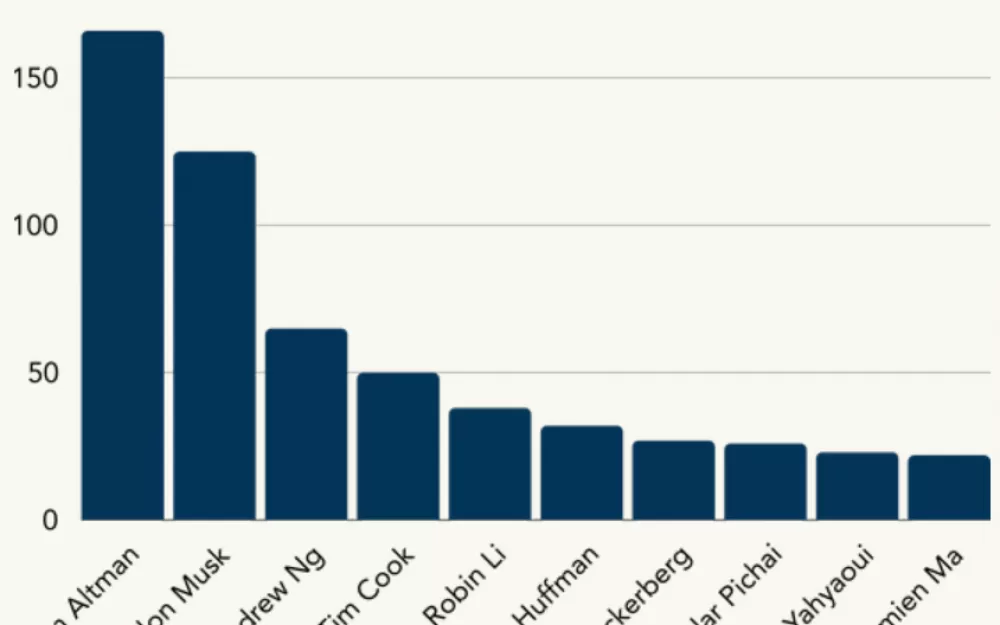
В проанализированных статьях встречались имена 283 людей, 159 человек цитировали. Чаще всего говорили про исполнительного директора OpenAI Сэма Альтмана (166 раз), главу Tesla и X/Twitter Илона Маска (125 раз) и сооснователя Google Brain Эндрю Ына (65 раз).
В целом, серьёзные ограничения накладывал крошечный размер самого датасета. Некоторые результаты пришлось правильно толковать. Например, в десятке самых популярных людей оказалась правозащитница Амира Яхьяуи, но все из 23 её упоминаний встречаются в единственной статье, целиком ей посвящённой.
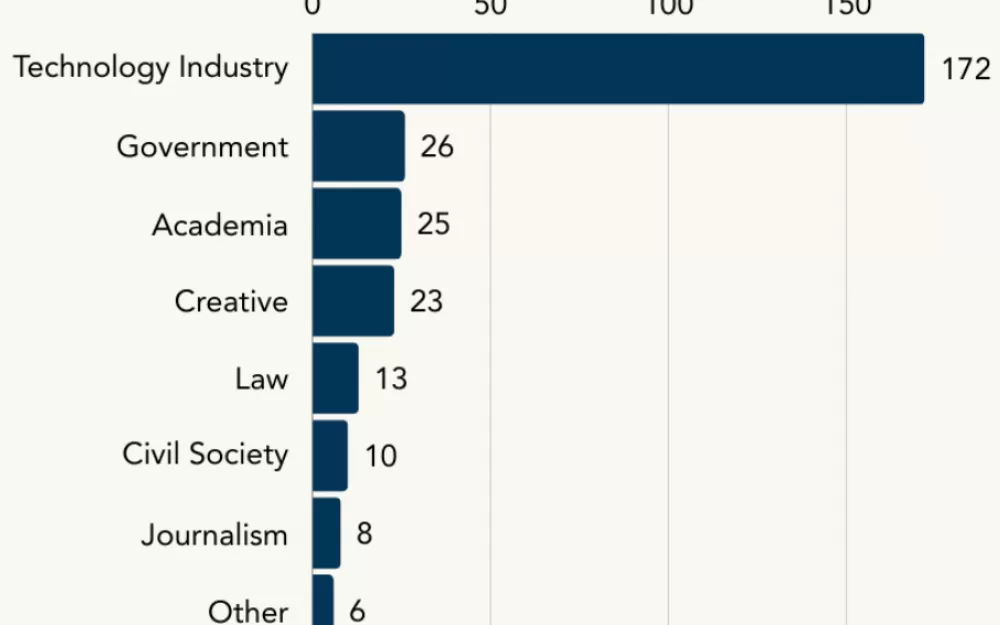
Поэтому более интересен анализ персон по отраслям. В подавляющем числе случаев упоминают и цитируют представителей компаний искусственного интеллекта: это 60,7 % упоминаний и 67,2 % цитат. В половине случаев (52 %) упоминают людей, которые явно работают в коммерческих компаниях, ещё 9 % нашлись из числа тех, которые работают в связанной с ИИ индустрии. Когда дело доходит до цитат, интересны в первую очередь мнения руководителей и топ-менеджеров таких компаний (33 % цитат).
Представилетей гражданского общества почти не упоминают. Лишь 3,5 % (10 человек) из числа упоминаемых — это разнообразные правозащитники; процитированных среди них всего 9 (5,66 %). Ситуация для членов научного сообщества, творческой сферы и государственных органов обстоит немногим лучше, но всё равно доля упоминаний и цитирирований для каждого из них никогда не превышает 10 %. Меньше правозащитников говорили разве что про журналистов и юристов.
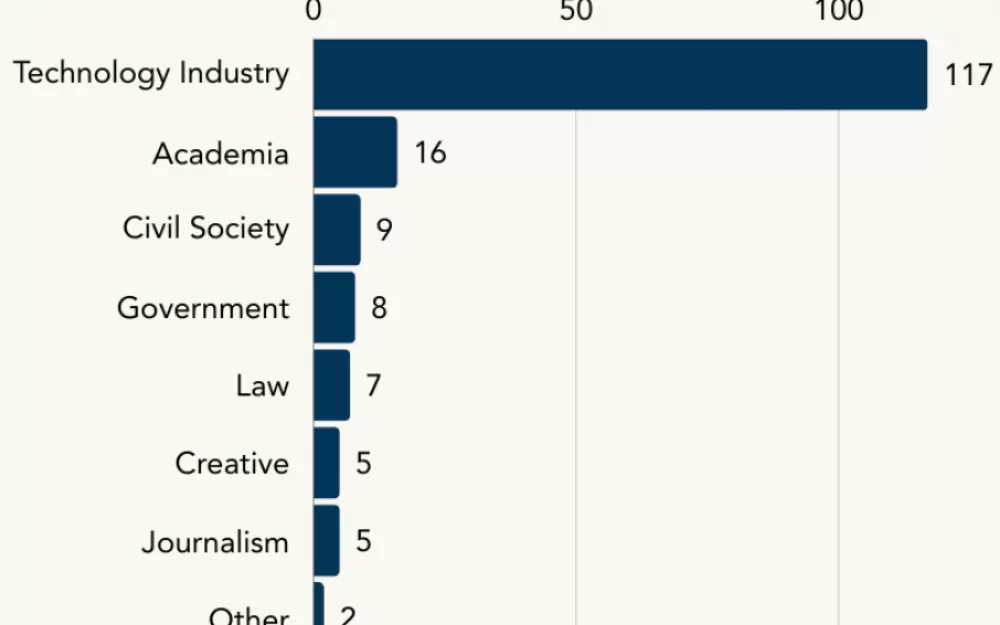
Цитаты неравноценны. Отчёт не только демонстрирует, что бигтех чаще получает микрофон. Контекст статей указывает: лучше всего способны рассказывать про искусственный интеллект сотрудники коммерческих организаций. «Экспертами» называют людей по типу Илона Маска и Сэма Альтмана, руководителей многомиллиардных компаний. При этом представителей научной среды и некоммерческих организаций обычно представляют как скептиков и критиков.
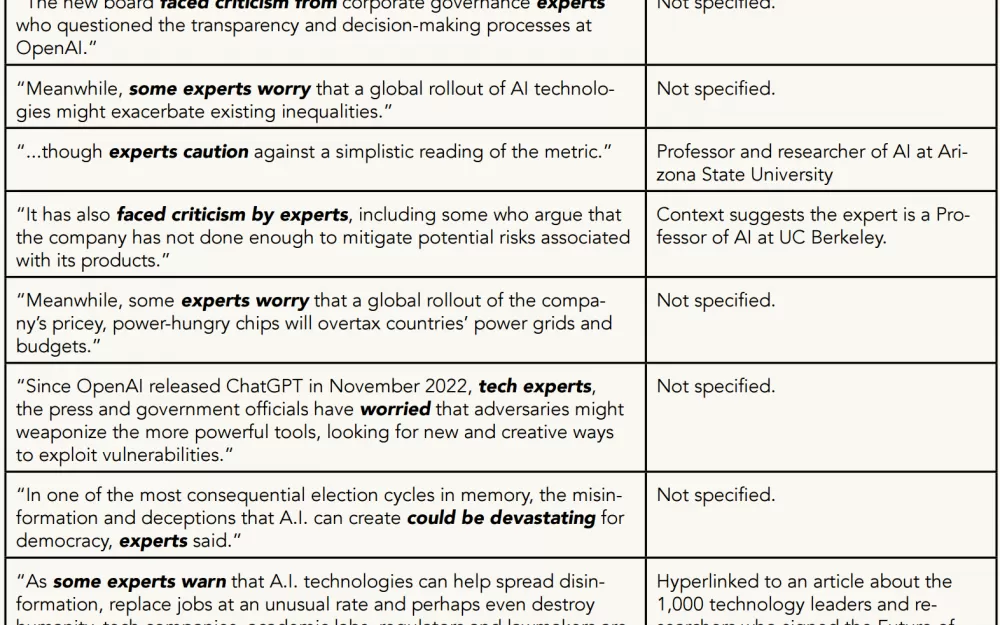
К примеру, в одной из статей (archive.is/kEpGq) про судебный иск Маска против OpenAI приводится цитата, где некий «сторонний эксперт» высказался про человечность GPT-4 и других подобных систем. В данном случае «сторонним экспертом» обозвали профессора Калифорнийского университета в Беркли. Отчёт критикует текст за отсутствие критериев того, кого считать сторонним, а кого внутренним экспертом.
Это не единичный пример. Отчёт выявил 18 фрагментов с упоминанием экспертов, из которых нашёл 8, где специалисты предостерегают или в чём-то сомневаются. Чаще всего личности скептиков не названы вовсе. В трёх случаях это либо профессора университетов, либо поддержавшие открытое письмо учёные.
Даже если представителям науки и дают возможность высказаться, внимание быстро уходит обратно на компании-гиганты. Например, в статье про биологическое оружие (archive.is/eIOj2) речь идёт про открытое письмо учёных и их беспокойство в отношении синтеза новых протеинов с помощью ИИ. Затем текст внезапно переключается на большие языковые модели: всю вторую половину статьи представители OpenAI и Anthropic рассказывают, что БЯМ никак не помогут создать биологическое оружие.
Computer Says Maybe критикует New York Times за неаккуратность в расставлении ссылок. Газета чаще даёт гиперссылки на коммерческие организации, чем на научные работы или релевантные сайты. В одном из примеров (archive.is/14qyC) статья издания рассказывает, как пользователи 4chan заставляли голос Эммы Уотсон зачитывать экстремитский материал «Моя борьба» и генерировали расистские заявления голосами судей США, задействовав для всего этого инструмент ElevenLabs. Ссылки на сайт этой компании в статье NYT присутствуют, а вот для гиперссылки на цитируемый исследовательский отчёт места не нашлось.
Исследование утверждает, что NYT часто прибегает к примитивным литературным тропам вида «герой против злодея». Это может быть противостояние между странами: статья (archive.is/bW6Yw) про соревнование США и Китая в области искусственного интеллекта прямо называет конкуренцию гонкой. В других случаях человек противопоставляется машине, раздуваются страхи — приём, который часто критикуется. Нарратив схватки Давида и Голиафа характерен для любых статей про OpenAI и Anthropic. Последняя описывается как мелкий игрок, превосходящий конкурента своими моральными качествами. В статье (archive.is/pAq1w) про вложение Amazon в $2,75 млрд в Anthropic приводится цитата, в которой инвестиция характеризуется как служащая интересам общества.
Отчёт также ругает NYT за ссылки на неясную и устаревшую информацию, которая пытается объяснить, что такое ИИ. Вообще, в датасете оказалось 180 употреблений слова «chatbot» в единственной и множественной формах, про «ChatGPT» говорят в 100 случаях, а вот лежащие в их основе технологии «large language model» (большая языковая модель) и «natural language processing» (обработка естественного языка) упоминаются меньше 20 раз каждая. Computer Says Maybe оценивает язык издания New York Times как запутанный и утверждает, что используемая терминология косвенно помогает крупным организациям сохранять сложившийся порядок вещей.
Документ «Selective Perspectives: A Content Analysis of The New York Times’ Reporting on Artificial Intelligence» опубликован на сайте организации Computer Says Maybe.












Написать комментарий