Опубликованы результаты исследования, можем ли мы научить языковые модели истолковывать исчезающие языки?
Поскольку почти половина из 7000 языков мира находится под угрозой исчезновения, сообщества носителей языков, принадлежащих к меньшинствам, работают над сохранением и возрождением своих языков[1]
При расшифровке древних и исчезающих языков ученые применяют такой подход как глоссирование - способ оформления текста, предполагающий наличие кратких пояснений к нему, которые помещаются в строчке между оригинальным текстом (или его транслитерацией) и переводом. Автоматизация создания глоссированного текста может сократить усилия аннотатора и поддержать согласованность в аннотированных корпусах. И применение LLM в этой задаче выглядит крайне привлекательно, ведь как известно, в эмбеддингах фраз на разных языках присутствует схожая близость слов, близких по контексту. Но вот справятся ли модели с такой задачей?
Основная проблема при работе с языками, находящимися под угрозой исчезновения, заключается в том, что почти во всех случаях очень мало маркированных данных. Это особенно важно для больших нейронных моделей, которые зависят от больших репрезентативных наборов данных для обучения.
В Университете Колорадо провели исследование по генерации глоссированного текста через LLM. Для этого они собрали крупнейший существующий корпус данных IGT из различных источников, охватывающий более 450 тыс. примеров на 1,8 тыс. языков.
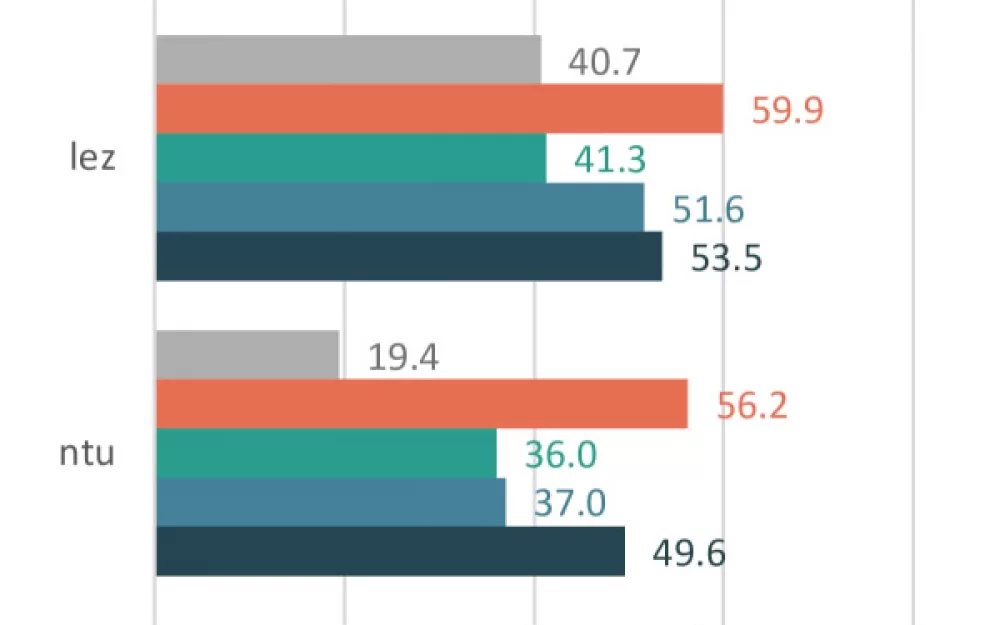
Исследователи проверили SOTA модели: Cohere R+, GPT-4o, Google Gemini 1.5 Pro и 2 традиционных метода.
В проверке участвовали 4 языка:
Gitksan - язык коренной народности Канады, в настоящий момент на планете на нем говорят 5680 человек.
Lezgi или лезгинский, язык Северного Кавказа, на котором говорят 630 тыс человек
Natugu - язык острова Нендо, на котором говорят 5900 человек
Uspanteko - язык Майя в Гватемале, на нем говорят 5100 человек.
Задача проверки заключалась в том, чтобы оценить, сколько глосс морфем совпадают между предсказанными и истинными глоссами.
Результаты представлены на графике
Применяя разные методы оптимизации, им удалось поднять точность LLM, но так и не превзойти стандартные способы. поэтому лингвистам LLM пока существенно не помогут, но работа продолжается.
первоисточник
P.S. Если вам интересны новости про генеративный ИИ, LLM, мультиагентов, я рассказываю об этом в своем Телеграм канале https://t.me/generative_ai_ru












Написать комментарий