
Показатели лучших моделей OpenAI рухнули в новом бенчмарке ARC-AGI-2
Новый бенчмарк AI ARC-AGI-2 значительно поднимает планку для тестов AI. В то время как люди могут легко решать эти задачи, даже высокоразвитые системы AI, такие как OpenAI o3, явно терпят неудачу.
Франсуа Шолле и его команда выпустили ARC-AGI-2, новую версию своего теста AI. Несмотря на то, что новый тест соответствует формату ARC-AGI-1, он обеспечивает, по словам команды, более сильный сигнал для измерения истинного интеллекта системы.
«Это тест AI, разработанный для измерения общего подвижного интеллекта, а не заученных навыков — набора никогда ранее невиданных задач, которые людям кажутся простыми, но с которыми современный AI сталкивается с трудностями», — пояснил Шолле на X.
Тест фокусируется на возможностях, которых все еще не хватает современным системам AI: интерпретация символов, многошаговое композиционное мышление и применение правил в зависимости от контекста.
Эталон был полностью откалиброван по результатам работы человека. В сеансах живого тестирования с 400 участниками были оставлены только те задачи, которые могли надежно решить несколько человек. Средний показатель сдающих тест без предварительной подготовки составил 60%, в то время как группа из 10 экспертов достигла 100%.
Результаты начального тестирования рисуют отрезвляющую картину. Даже самые передовые системы работают плохо. Чисто языковые модели, такие как GPT-4.5, Claude 3.7 Sonnet и Gemini 2, набирают ноль процентов. Модели с базовыми цепочками рассуждений, такие как Claude 3.7 Sonnet Thinking, R1 и o3-mini, набирают только от нуля до одного процента.

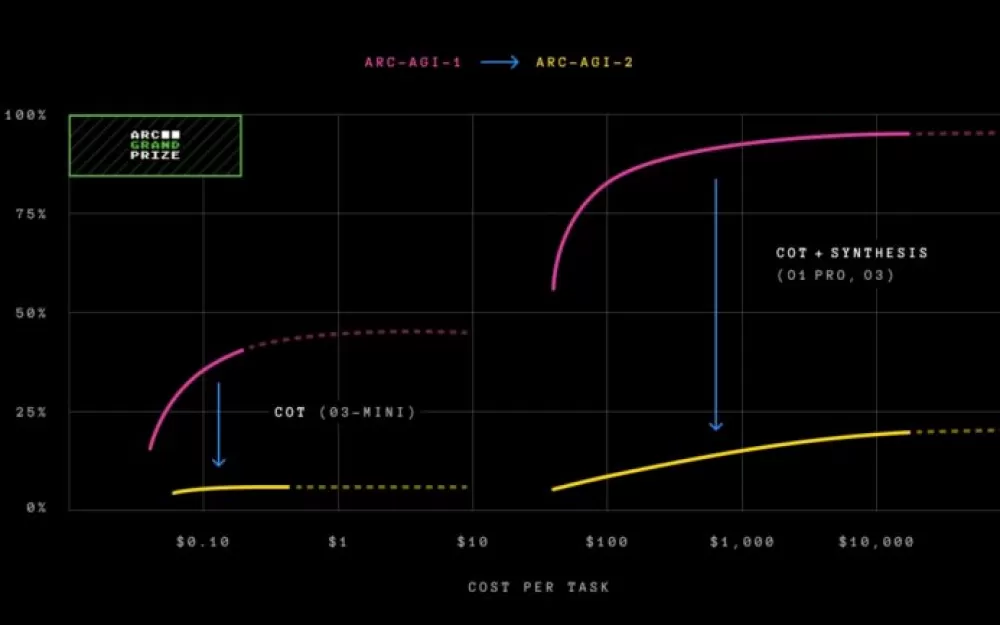
Модель o3-low от OpenAI показала особенно заметное падение производительности, упав с 75,7% на ARC-AGI-1 до примерно 4% на ARC-AGI-2. Победители ARC Prize 2024, команда ARChitects, испытали аналогичное падение с 53,5% до 3%.
Некоторые модели, особенно o3-high, до сих пор не прошли тщательного тестирования или полагаются на прогнозы, а это значит, что их фактическая производительность может быть выше.
ARC-AGI-2 представляет новую метрику эффективности. Теперь бенчмарк оценивает не только способность решать проблемы, но и то, насколько эффективно эта способность используется. Стоимость служит исходной метрикой, позволяя проводить прямые сравнения между производительностью человека и AI.
«Мы знаем, что поиск методом грубой силы в конечном итоге может решить ARC-AGI (при наличии неограниченных ресурсов и времени для поиска). Это не будет представлять собой настоящий интеллект», — поясняет Фонд премии ARC. «Интеллект заключается в эффективном, а не исчерпывающем поиске решения».
Разрыв в эффективности между человеческим и искусственным интеллектом огромен. В то время как группа экспертов-людей решает 100% задач примерно за $17 за задачу, модель OpenAI o3-low тратит около $200 за задачу, чтобы достичь точности всего в четыре процента.
Конкурс ARC Prize 2025 стартует одновременно с ARC-AGI-2, предлагая общий призовой фонд в размере $1 млн. Главный приз в размере $700 000 требует достижения 85-процентной точности в частном оценочном наборе. Дополнительные награды включают $125 000 в качестве гарантированных призов за прогресс и $175 000 в качестве еще не объявленных призов.
Конкурс проводится на Kaggle с марта по ноябрь 2025 года. В отличие от публичной таблицы лидеров на arcprize.org, правила Kaggle ограничивают вычислительную мощность участников примерно $50 за одну заявку и запрещают использование интернет-API.
Хотя оригинальный тест ARC-AGI-1 от 2019 года считался одним из самых сложных тестов AI и сигнализировал о росте моделей рассуждений, ни одна из версий не претендует на достижение AGI. По словам команды разработчиков, оба теста могут остаться нерешенными, не достигнув искусственного интеллекта в целом.
Источник













Написать комментарий