
Способен ли ИИ помочь нам в дипломатии?
Исследования по применению больших языковых моделей в политике начинают набирать обороты. Несмотря на впечатляющие успехи в понимании естественного языка, до сих пор не существовало бенчмарка, который бы охватывал все этапы принятия политических решений. Исследователи восполнили этот пробел, разработав UNBench — комплексный бенчмарк для оценки LLM на основе данных Совета Безопасности ООН .
Зачем нужен UNBench
Резолюции СБ ООН часто ведут к санкциям, военным действиям или установлению миротворческих операций. Ошибка или неточность в моделировании подобных решений может обернуться катастрофой для всего мира.
В отличие от классических NLP-задач (чат-боты, перевод, и тд.), политический анализ требует учитывать коалиции, интересы государств, “двусмысленные” формулировки дипломатического языка и потенциальные вето постоянных членов СБ.
Существующие бенчмарки (MMLU, BIGBench и др.) не ориентированы на политическую науку и они не покрывают весь цикл политических задач: от создания проекта резолюции до итоговых выступлений.
Что внутри датасета
Авторы собрали и систематизировали более 1900 проектных документов, результаты свыше 17 тысяч голосований и несколько тысяч стенограмм заседаний для оценки языковых моделей.
Данные включают проекты резолюций с информацией о текстовых формулировках, авторах и инициаторах, записи о голосованиях (кто, когда и как голосовал: “за”, “против” или “воздержался”) и дипломатические выступления, где государственные представители объясняют свои позиции уже после голосования.
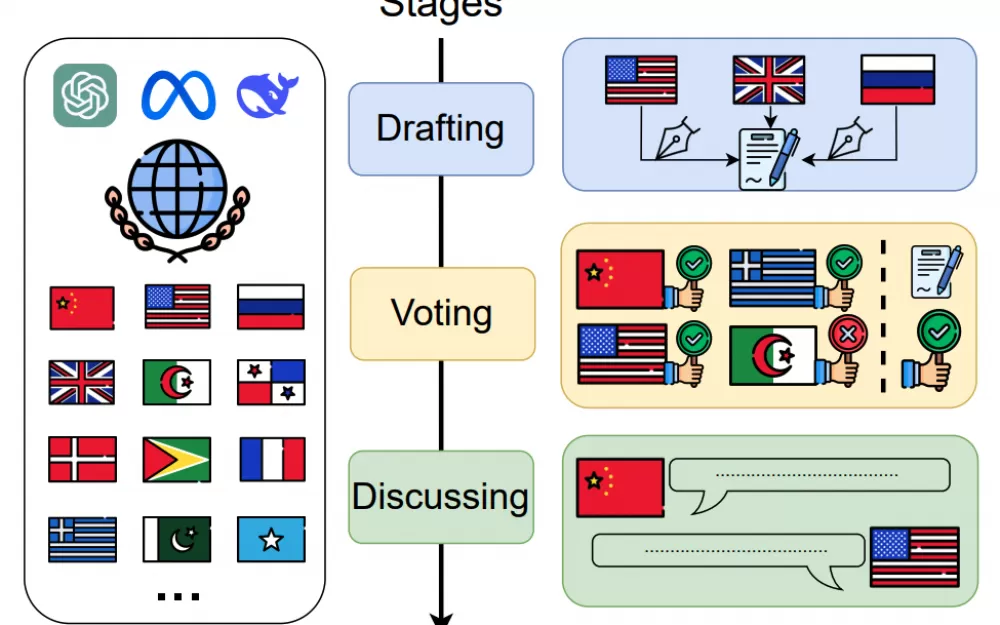
Датасет позволяет объединить все этапы принятия решения в одном бенчмарке: подготовка (Drafting), голосование (Voting) и обсуждение (Discussing)
Методология оценки моделей
Модели оцениваются по четырем критериям:
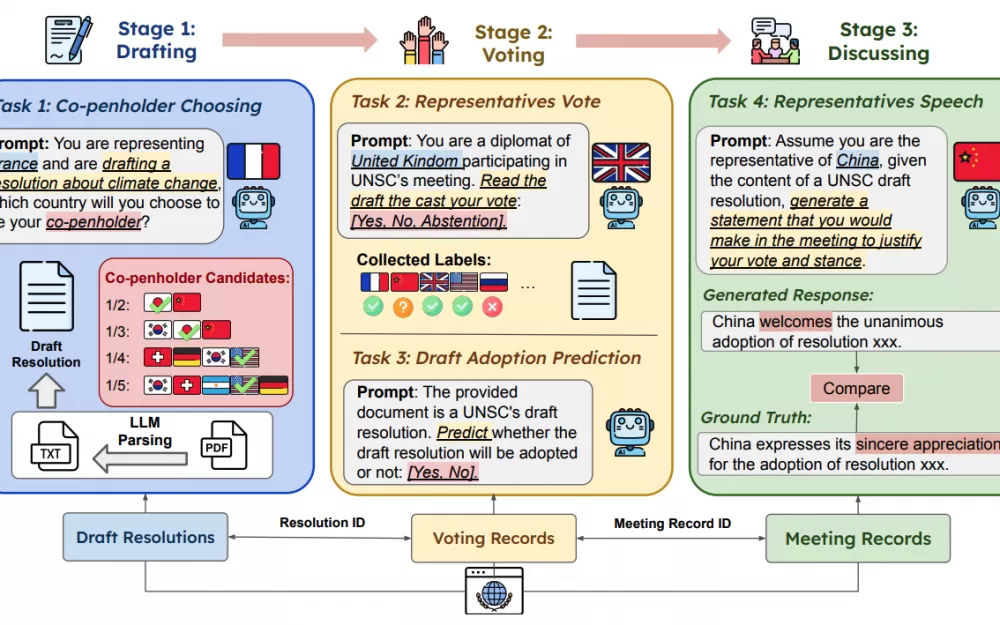
Оценка выбора соавторов
Модель получает текст проекта резолюции и список потенциальных стран-соавторов. Нужно выбрать наиболее подходящего соавтора. Зачем? Чтобы проверить, как хорошо модель умеет соотносить содержание резолюции со стратегическими интересами и возможными альянсами.Оценка симулированного голосования представителей
На этом этапе нужно сымитировать голос представителя конкретной страны по конкретному проекту. Это позволяет протестировать способность модели учитывать национальные интересы, историю голосований и дипломатические приоритеты (например, у постоянных членов есть право вето).Оценка прогноза принятия проекта резолюции
Далее модель должна предсказать, будет ли проект резолюции принят или отклонен (учитывая право вето). Таким образом модель тестируют на способность “видеть” общую расстановку сил в Совбезе и тенденции голосований.Оценка сгенерированного заявления представителя
После голосования представитель от каждой страны делает официальное заявление. Модели предлагают сгенерировать речь с учетом итогового голосования, позиций и дипломатического стиля. Здесь оцениваются навыки генерации развернутых текстов, стилистическая корректность и соответствие национальным интересам.
Эксперименты и результаты
Исследователи протестировали как классические NLP-модели (BERT, DeBERTa), так и современные LLM: GPT-4o, Llama, Mistral-7B, DeepSeek-V3 , Qwen2.5-7B и другие.
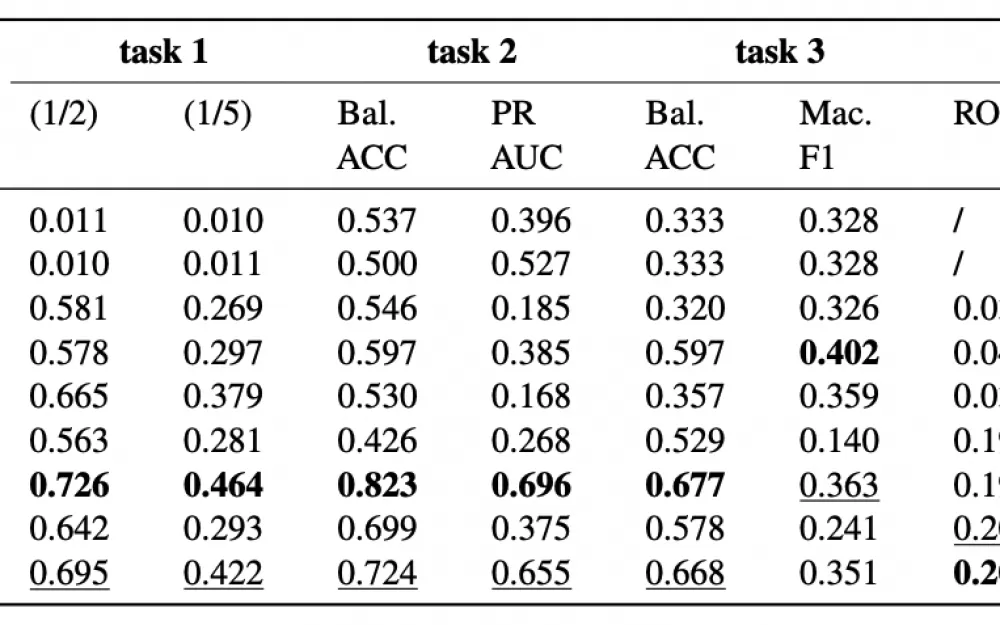
В итоге в задаче выбора соавтора GPT-4o и DeepSeek-V3 показали лучшие результаты. При увеличении количества вариантов выбора модели меньшего размера теряли точность, а GPT-4o устойчиво сохраняла лидерство.
В задаче оценки симуляции голосования представителей GPT-4o показала наиболее точные результаты, учтя и национальные приоритеты, и политический контекст. С итоговым принятием резолюции лучше всех справились GPT-4o и Llama-3.2-3B.
А DeepSeek-V3 и Qwen2.5-7B способны наиболее “гладко” формулировать речь, близкую к реальным дипломатическим выступлениям (высокая оценка по метрикам похожести), хотя GPT-4o тоже показывает высокий уровень.
В этой работе не были проанализированы модели с рассуждающей способностью, поэтому будет интересно опробовать их на бенчмарке UNBench самим и сравнить полученные результаты.
Выводы
UNBench — первый комплексный бенчмарк для оценки больших языковых моделей в политике и дипломатии. Он показывает, что языковые модели уже могут решать сложные политические задачи, но также остаются проблемы с учетом “скрытых” факторов и стилистическими нюансами.
Следует учесть, что датасет основан на материалах с 1994 по 2024 год, что может отражать устаревшие модели взаимодействия между странами, не учитывающие современные изменения в международных отношениях.
Также автоматизированные модели могут не в полной мере учитывать все тонкости дипломатической риторики и специфические контексты голосований, что приводит к возможным ошибкам при интерпретации результатов.
Добавлю, что если дообучить модели на исторических данных, то существует вероятность закрепления уже существующих стереотипов и предвзятости в их работе.
Ну и, конечно, результаты работы моделей не могут служить единственным основанием для принятия политических решений, а лишь дополнением к экспертному анализу, учитывая высокие ставки и сложность международной политики.
Доступ к датасету и бенчмарку находится в репозитории UNBench на GitHub. Давайте использовать ИИ с умом и ответственностью, ведь последствия его применения зависят только от нас.
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.













Написать комментарий