
Система вознаграждений RLSP: Как она меняет подход к обучению языковых моделей
Группа исследователей из Массачусетского технологического института, Корнеллского университета, Вашингтонского университета и Microsoft Research разработала фреймворк под названием «Reinforcement Learning via Self-Play» , который обучает большие языковые модели тратить больше времени на решение проблем. Подход отражает методы, используемые в успешных моделях AI, таких как o1, o3 от OpenAI, R1 от Deepseek и Gemini от Google.
RLSP работает в три этапа: во-первых, модель учится на примерах человеческого или AI-мышления (SFT). Затем она вознаграждается за изучение различных подходов к проблемам (RL). Наконец, система проверяет ответы, чтобы обеспечить точность и избежать сокращений (Verifier).
Тестирование показывает многообещающие результаты. При применении к моделям Llama RLSP улучшил результаты в наборе данных MATH 500 на 23%. Модель Qwen2.5-32B-Instruct показала 10%-ный прирост в математических задачах AIME 2024. Даже при базовых вознаграждениях за проявленную работу модели развивали интересное поведение, например, возврат назад, исследование нескольких решений и перепроверку своих ответов.
Эти результаты в значительной степени соответствуют выводам, представленным командой Deepseek R1 и R1-Zero , а также недавними исследованиями исследователей из IN.AI, Университета Цинхуа и Университета Карнеги — Меллона.
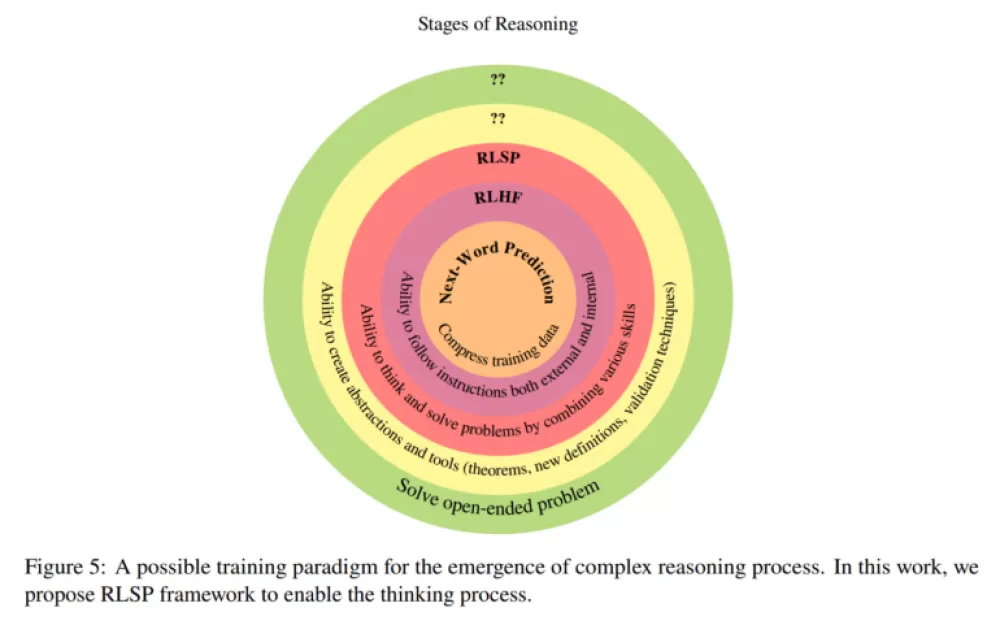
Наиболее примечательным открытием являются не просто лучшие результаты тестов, а то, как модели учатся решать проблемы. Даже без конкретных обучающих примеров, но с небольшими наградами за исследование, модели выработали несколько полезных поведений для разных типов проблем.
Исследователи думают, что знают, почему это работает: недавние исследования показывают, что рассуждения «цепочки мыслей» — когда модели записывают свои мысли шаг за шагом — дают им больше вычислительной мощности для решения проблем. RLSP поощряет модели создавать новые пути рассуждений посредством «самостоятельной игры», подобно тому, как AI научился осваивать такие игры, как шахматы и го.
Система вознаграждения поощряет модели показывать всю свою работу, даже если некоторые подходы не приводят к правильному ответу. Когда модель находит правильное решение в результате более длительного процесса рассуждений, она получает полный кредит. Это создает новые примеры пошаговых рассуждений, которые помогают модели совершенствоваться.
Команда отмечает несколько оставшихся проблем. Они хотят узнать, как модели могли бы корректировать время своего мышления в зависимости от сложности задачи — тратя меньше времени на простую математику и больше на сложные доказательства. Им также интересно, как длина контекста влияет на рассуждения и действительно ли эти поведения выходят за рамки того, что модели видят в обучающих данных.
Другие открытые вопросы включают в себя вопрос о том, может ли чистое обучение с подкреплением без поощрений за исследование улучшить рассуждения в более крупных моделях, и какие дополнительные методы обучения могут помочь моделям развить навыки мышления более высокого уровня, такие как построение теорем и решение открытых задач.
Источник













Написать комментарий