
CAPA: новый инструмент для обнаружения сходства ошибок в LLM
Новое исследование того, как языковые модели оценивают друг друга, выявило тревожную закономерность: по мере того, как эти системы становятся более сложными, они все чаще склонны разделять одни и те же слепые зоны.
Исследователи из институтов в Тюбингене, Хайдарабаде и Стэнфорде разработали новый инструмент измерения под названием CAPA (Chance Adjusted Probabilistic Agreement), чтобы отслеживать, как языковые модели пересекаются в своих ошибках за пределами того, что можно было бы ожидать только от их показателей точности. Их выводы показывают, что языковые модели, как правило, благоприятствуют другим LLM, которые совершают ошибки, похожие на их собственные.
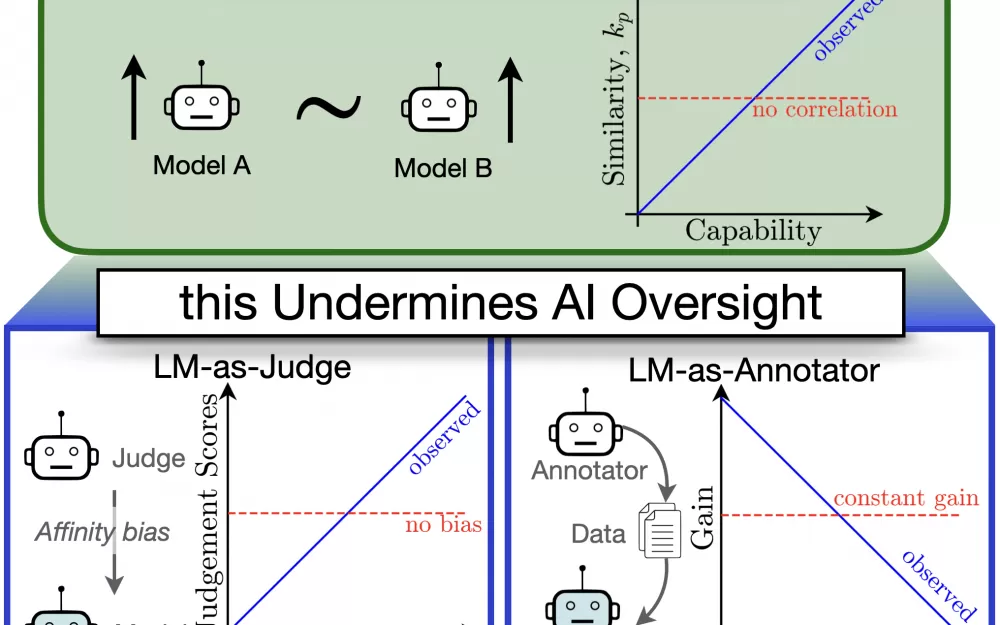
Когда языковым моделям поручали оценивать выводы других моделей, они последовательно давали лучшие оценки системам, которые имели схожие с ними паттерны ошибок, даже после учета фактических различий в производительности. Исследователи сравнивают такое поведение с «предвзятостью по сходству» в человеческом найме, когда интервьюеры бессознательно благоприятствуют кандидатам, которые напоминают им самих себя.
Команда также исследовала, что происходит, когда более сильные модели обучаются на основе контента, созданного более слабыми. Они обнаружили, что более существенные различия между моделями приводят к лучшим результатам обучения, вероятно, потому, что разнородные модели обладают дополнительными знаниями. Это открытие помогает объяснить, почему прирост производительности в подходах к обучению «от слабого к сильному» варьируется в зависимости от разных задач.
Проанализировав более 130 языковых моделей, исследователи выявили тревожную закономерность: по мере того, как модели становятся более способными, их ошибки становятся все более похожими. Эта тенденция вызывает опасения по поводу безопасности, особенно по мере того, как системы AI берут на себя все большую ответственность за оценку и контроль других систем AI.
«Наши результаты указывают на риск возникновения общих слепых зон и сбоев при использовании контроля со стороны AI, что вызывает опасения относительно безопасности», — пишут исследователи.
Исследовательская команда подчеркивает важность внимания как к сходству моделей, так и к разнообразию ошибок, отмечая, что необходимы дополнительные исследования для расширения их метрики для оценки ответов в свободной форме и способностей к рассуждению больших языковых моделей.
Источник













Написать комментарий