Команда Hugging Face представила собственную открытую реализацию агента DeepResearch от OpenAI
Инженеры Hugging Face рассказали в блоге, что вдохновились функцией DeepResearch от OpenAI и решили за 24 часа разработать собственную реализацию. В итоге получился поисковой агент, который может автономно просматривать веб-страницы, искать на них нужную информацию, скачивать файлы с сайтов, анализировать их и агрегировать всё в ответ.
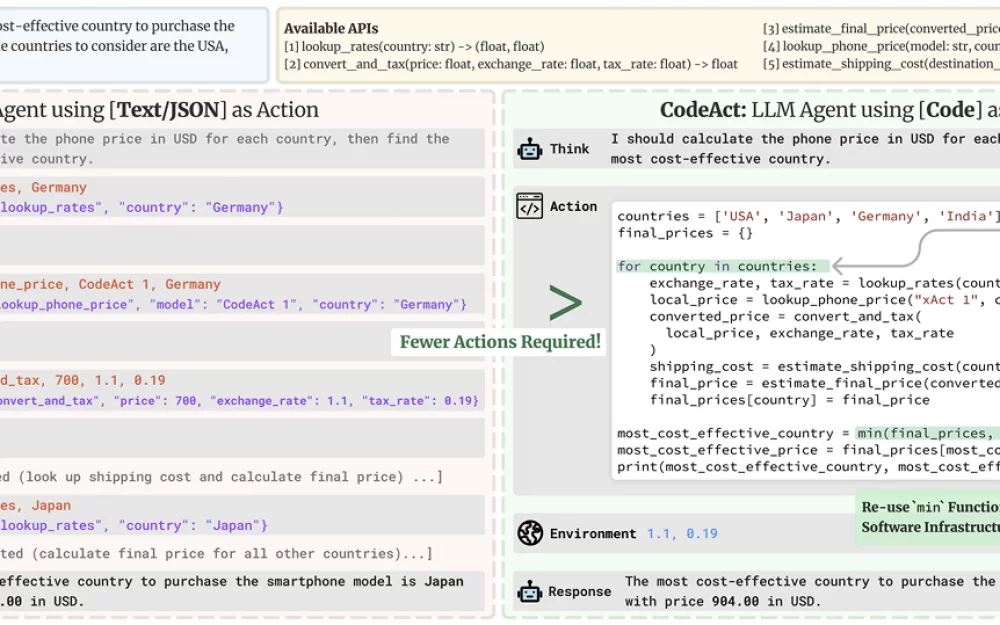
Для улучшения производительности исследователи использовали CodeAgent — агента, который может выражать свои действия в виде кода. Авторы проекта уверены что длинную последовательность сложных действий эффективнее описать кодом, а не естественным языком.
Также команда Hugging Face использовала в своей работе инструменты от разработчиков Microsoft Research:
Текстовый браузер. У исследователей было всего 24 часа на разработку, поэтому решили выбрать примитивную реализацию браузера, которая отображает страницы в виде текста. Этот способ плохо подходит людям, но нейросетям проще анализировать именно тексты. В будущем команда планирует перейти на «визуальный браузер».
Инспектор текста. На веб-страницах могут находиться файлы с полезной информацией, поэтому важно иметь возможность скачивать их, преобразовывать в Markdown и обрабатывать с помощью языковой модели. Инспектор в проекте Hugging Face может работать с HTML, HTM, XLSX, PPTX, WAV, MP3, FLAC, PDF и DOCX. Важно отметить, что с помощью инструмента нельзя обрабатывать изображения.
Готовый поисковой агент набрал 67% правильных ответов в бенчмарке GAIA и 55% в Magentic-One. Код реализации DeepResearch от Hugging Face опубликовали на GitHub.
Ещё одну открытую реализацию поискового агента DeepResearch представил разработчик под никнеймом mshumer. Он использовал комбинацию из сервисов OpenRouter API, SERPAPI и Jina.












Написать комментарий