
SwiftKV: как снизить затраты и ускорить логический вывод больших языковых моделей
Исследовательская группа Snowflake AI представляет SwiftKV - решение, разработанное для повышения производительности LLM-выводов и снижения связанных с этим затрат. SwiftKV использует методы кэширования пар «ключ-значение» для повторного использования промежуточных вычислений во время выводов. Устраняя избыточные вычисления, оно оптимизирует процесс вывода и повышает эффективность использования LLM.
Конструкция SwiftKV ориентирована на вычислительную мощность больших языковых моделей. Обычные конвейеры логического вывода часто повторно вычисляют одни и те же операции для нескольких запросов, что приводит к неэффективности. SwiftKV представляет собой уровень кэширования, который определяет и сохраняет результаты вычислений, которые можно использовать повторно. Такой подход ускоряет логический вывод и снижает требования к ресурсам, что делает его практичным выбором для организаций, стремящихся оптимизировать свои операции с AI.
SwiftKV включает систему памяти «ключ-значение» в архитектуру LLM. Её работу можно описать следующим образом:
Кэширование пар «ключ-значение»: во время логического вывода SwiftKV фиксирует промежуточные активации (ключи) и соответствующие им результаты (значения). Для аналогичных запросов он извлекает предварительно вычисленные значения, а не пересчитывает их.
Эффективное управление хранилищем: механизм кэширования использует такие стратегии, как удаление наименее часто используемых (LRU) элементов, для эффективного управления памятью, гарантируя, что кэш остается полезным без чрезмерного потребления ресурсов.
Бесшовная интеграция: SwiftKV совместим с существующими платформами LLM, такими как Transformers от Hugging Face и LLaMA от Meta, что позволяет легко внедрять его без значительных изменений в существующих конвейерах.
Преимущества SwiftKV включают в себя:
Снижение затрат: благодаря отсутствию избыточных вычислений SwiftKV значительно сокращает затраты на логический вывод. По данным Snowflake AI Research, в некоторых сценариях затраты снижаются на 75%.
Повышенная пропускная способность: механизм кэширования сокращает время логического вывода, повышая скорость отклика.
Экономия энергии: меньшие вычислительные требования приводят к снижению энергопотребления, поддерживая устойчивые методы использования AI.
Масштабируемость: SwiftKV хорошо подходит для крупномасштабного развертывания, удовлетворяя потребности предприятий, расширяющих свои возможности в области AI.
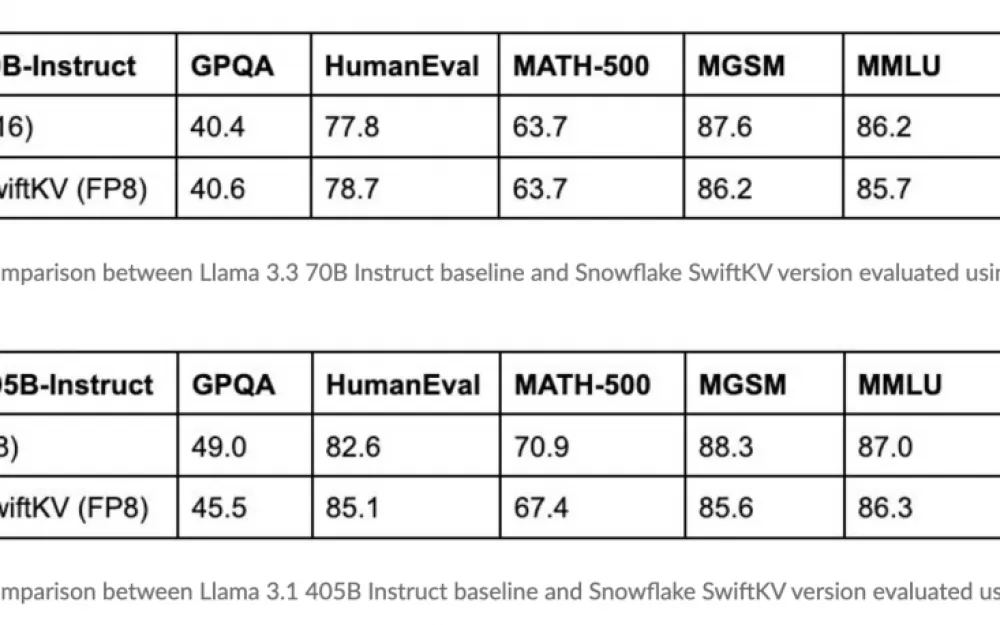
Результаты оценки SwiftKV, проведённой Snowflake AI Research, дают ценную информацию о его эффективности. Например, интеграция SwiftKV с моделями Meta LLaMA привела к снижению затрат на вывод данных на 75% без ущерба для точности или производительности. Эти результаты показывают, что с помощью такого подхода можно повысить эффективность.
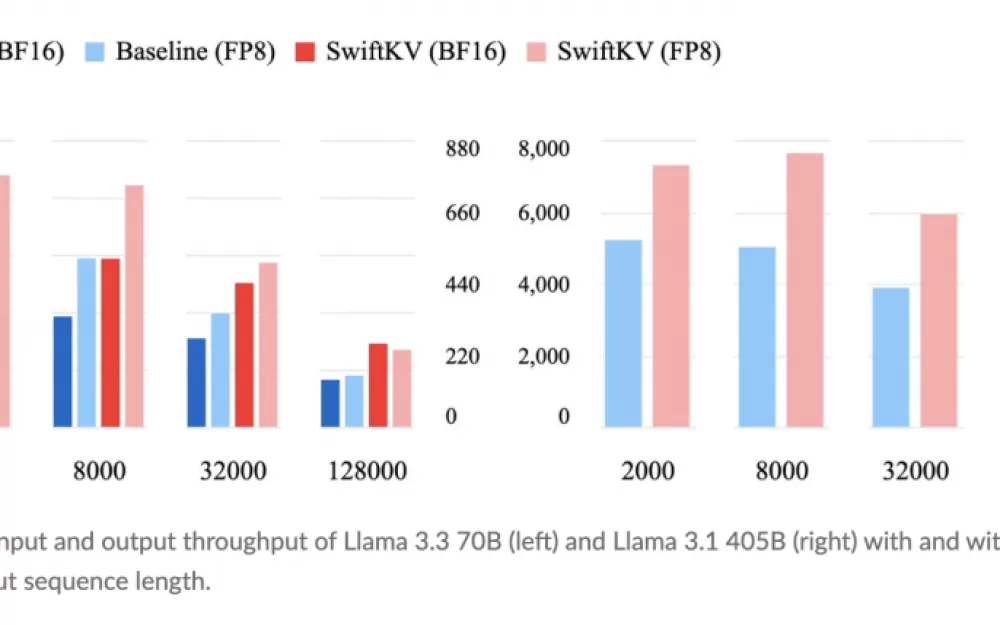
Кроме того, тесты демонстрируют значительное сокращение времени выполнения логических выводов даже для более крупных моделей. Система кэширования обеспечивает более быструю обработку сложных запросов. Такое сочетание экономичности и оптимизации производительности делает SwiftKV привлекательным выбором для организаций, стремящихся к недорогому масштабированию AI-решений.
Открытый исходный код SwiftKV способствует сотрудничеству в сообществе специалистов по искусственному интеллекту. Делясь этой технологией, Snowflake AI Research приглашает разработчиков, исследователей и предприятия изучать и расширять её возможности, способствуя инновациям в области эффективности LLM.
По мере развития области искусственного интеллекта такие инструменты, как SwiftKV, будут продолжать формировать эффективные и устойчивые технологии. Благодаря открытому исходному коду более широкое сообщество может вносить свой вклад в его развитие и применение. Обеспечивая более экономичное и масштабируемое использование больших языковых моделей, SwiftKV подчёркивает важность инноваций для того, чтобы AI стал по-настоящему преобразующим как для бизнеса, так и для разработчиков.
Источник













Написать комментарий