
Meta* предлагает новые масштабируемые слои памяти
По мере того как предприятия продолжают внедрять большие языковые модели в различные приложения, одной из ключевых задач, с которыми они сталкиваются, является повышение фактических знаний моделей и уменьшение галлюцинаций. В новой статье исследователи из Meta AI предлагают «масштабируемые слои памяти», которые могут стать одним из нескольких возможных решений этой проблемы.
Масштабируемые слои памяти добавляют больше параметров в LLM, увеличивая их способность к обучению без необходимости дополнительных вычислительных ресурсов. Это полезно для приложений, где можно выделить дополнительную память для фактических знаний, но при этом требуется скорость вывода более легких моделей.
Традиционные языковые модели используют «плотные слои» для кодирования огромного количества информации в их параметрах. В плотных слоях все параметры используют свою полную емкость и в основном активируются одновременно во время вывода. Плотные слои могут изучать более сложные функции по мере их увеличения, но увеличение их размеров требует дополнительных вычислительных и энергетических ресурсов.
В отличие от этого, для простых фактических знаний намного более эффективными и интерпретируемыми были бы более простые слои с архитектурами ассоциативной памяти, напоминающими таблицы поиска. Именно этим занимаются памятные слои. Они используют простые разреженные активации и механизмы поиска по ключ-значение для кодирования и извлечения знаний. Разреженные слои занимают больше памяти, чем плотные слои, но одновременно используют только небольшую часть параметров, что делает их гораздо более вычислительно эффективными.
Слои памяти существуют уже несколько лет, но редко используются в современных архитектурах глубокого обучения. Они не оптимизированы для современных аппаратных ускорителей.
Современные передовые LLM обычно используют MoE, которая использует механизм, отдаленно похожий на памятные слои. Модели MoE состоят из множества небольших экспертных компонентов, специализирующихся на конкретных задачах. Во время вывода механизм маршрутизации определяет, какой эксперт будет активирован на основе входной последовательности. PEER-архитектура, недавно разработанная Google DeepMind, расширяет MoE до миллионов экспертов, обеспечивая более детальный контроль над параметрами, которые активируются во время вывода.
Слои памяти не требуют больших вычислительных ресурсов, но потребляют много памяти, что создает конкретные проблемы для современных аппаратных и программных фреймворков. В своей статье исследователи из Meta предлагают несколько модификаций, которые решают эти проблемы и позволяют использовать их в масштабе.
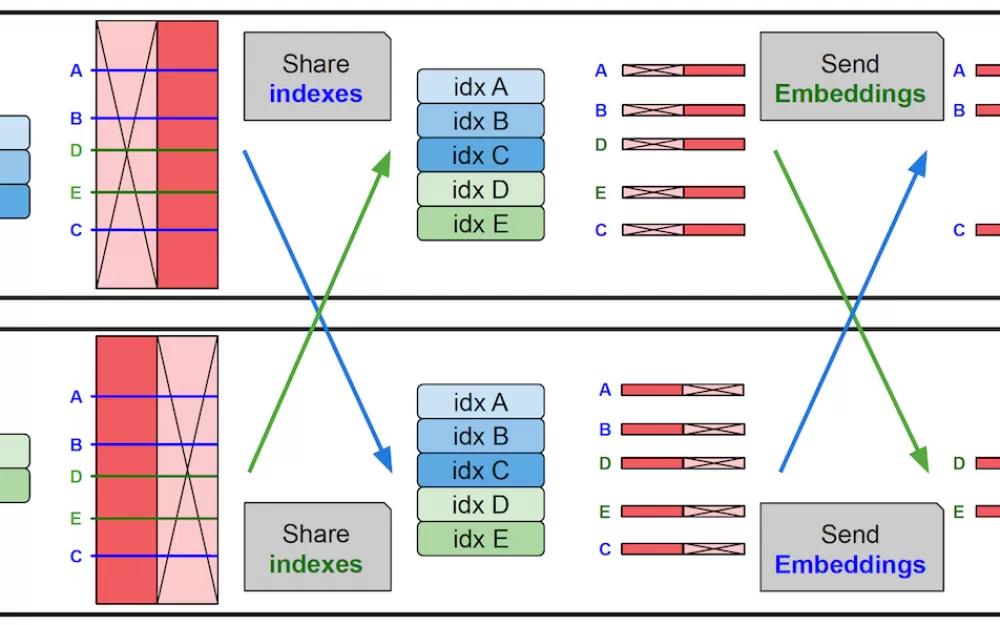
Во-первых, исследователи настроили слои памяти для параллелизации, распределяя их по нескольким GPU для хранения миллионов пар ключ-значение без изменения других слоев в модели. Они также реализовали специальное ядро CUDA для обработки операций с высокой пропускной способностью памяти. Кроме того, они разработали механизм совместного использования параметров, который поддерживает единый набор параметров памяти для нескольких слоев памяти внутри модели. Это означает, что ключи и значения, используемые для поиска, разделяются между слоями. Эти модификации позволяют внедрять слои памяти в LLM без замедления модели.
«Слои памяти с их разреженными активациями прекрасно дополняют плотные сети, обеспечивая увеличенную емкость для усвоения знаний при низких вычислительных затратах», пишут исследователи. «Они могут эффективно масштабироваться и предоставляют практикам привлекательное новое направление для компромисса между памятью и вычислениями.
Для тестирования слоев памяти исследователи модифицировали модели Llama, заменив один или несколько плотных слоев на общий слой памяти. Они сравнили модели с улучшенной памятью с плотными LLM, а также с моделями MoE и PEER по нескольким задачам, включая ответы на фактические вопросы, научные и общие знания о мире, а также программирование.
Их результаты показывают, что модели с памятью значительно превосходят плотные базовые модели и конкурируют с моделями, использующими в 2-4 раза больше вычислительных ресурсов. Они также соответствуют производительности моделей MoE с тем же бюджетом на вычисления и количеством параметров. Особенно заметна производительность модели на задачах, требующих фактических знаний. Например, в задаче ответов на фактические вопросы модель с памятью и 1,3 миллиарда параметров приближается к производительности Llama-2-7B, которая обучалась на в два раза большем количестве токенов и с 10-кратным увеличением вычислительных ресурсов.
Более того, исследователи обнаружили, что преимущества моделей с памятью остаются стабильными при увеличении размера модели, масштабируя свои эксперименты от 134 миллионов до 8 миллиардов параметров.
«Учитывая эти результаты, мы настоятельно рекомендуем интегрировать слои памяти во все архитектуры AI следующего поколения»,- пишут исследователи, добавляя, что до сих пор есть много возможностей для улучшений.
«В частности, мы надеемся, что будут разработаны новые методы обучения, которые еще больше повысят эффективность этих слоев, позволяя уменьшить забывание, снизить количество галлюцинаций и обеспечить непрерывное обучение.»
*Meta и её продукты (Facebook, Instagram) запрещены на территории Российской Федерации
Источник












Написать комментарий