
RetroLLM: расширение возможностей больших языковых моделей для получения точных данных в процессе генерации
Исследователи разработали более оптимизированный подход, который помогает системам искусственного интеллекта обрабатывать информацию. Новая система под названием RetroLLM объединяет два ранее раздельных этапа — поиск информации и написание текста — в единый процесс.
Команда из Китайского народного университета, Университета Цинхуа и лаборатории Huawei «Pоisson» разработала RetroLLM, чтобы сделать системы искусственного интеллекта более эффективными. Традиционные системы RAG (генерация с дополненным поиском) должны были работать в два этапа: сначала находить релевантную информацию, а затем создавать на её основе текст. RetroLLM выполняет обе задачи одновременно, потребляя меньше вычислительной мощности и обеспечивая более точные результаты.
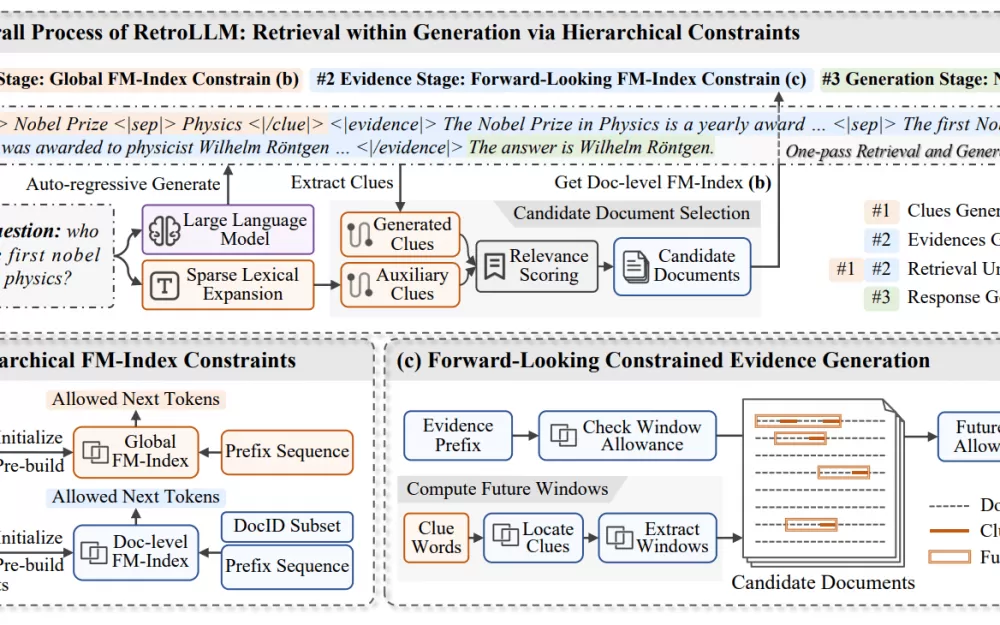
Система работает в три основных этапа. Во-первых, она создаёт «подсказки» — ключевые слова или фразы на основе исходного вопроса. Например, если кто-то спрашивает о первом лауреате Нобелевской премии по физике, система определяет такие термины, как «Нобелевская премия» и «физика».
Далее RetroLLM обрабатывает информацию с помощью нескольких передовых методов. Он одновременно оценивает несколько потенциальных текстовых путей (ограниченный поиск с возвратом), как бы исследуя различные ветви дерева решений и фокусируясь на наиболее перспективных. Система также может предсказывать, какие разделы будут полезны, до их полной обработки (ограниченное декодирование с прогнозированием), что помогает ей не тратить время на нерелевантный контент.
Для эффективной обработки больших объёмов текста RetroLLM использует сложную систему индексирования (иерархические ограничения FM-индекса), которая работает как подробная дорожная карта, помогая быстро находить именно ту информацию, которая нужна на разных уровнях детализации.
В ходе тестирования RetroLLM показал впечатляющие результаты, достигнув на 10–15% более высокой точности, чем существующие системы. Она особенно хорошо справляется со сложными вопросами, требующими объединения информации из нескольких источников.
Система адаптирует свой подход к каждому вопросу. Для простых запросов ей может потребоваться лишь несколько ключевых фактов. Для более сложных вопросов она автоматически выполняет более глубокий поиск и обращается к дополнительным источникам.
Хотя RetroLLM в целом потребляет меньше вычислительной мощности, исследователи обнаружили одно ограничение: при обработке отдельных запросов он работает немного медленнее, чем более простые системы. Команда считает, что использование комбинации небольших и больших моделей может помочь решить эту проблему в будущем.
Источник












Написать комментарий