
OpenAI обучила модели o1 и o3 «следовать» политике безопасности компании
В пятницу OpenAI представила новое поколение моделей искусственного интеллекта под названием o3, утверждая, что они превосходят предыдущие версии, такие как o1, и любые другие модели, выпущенные ранее. Эти улучшения достигнуты благодаря увеличению вычислительных мощностей при тестировании, о чем активно писали в прошлом месяце. OpenAI также использовала новую парадигму безопасности для обучения своих моделей серии o.
В тот же день OpenAI опубликовала исследование о "совещательном согласовании", описывающее новый метод обеспечения соответствия моделей AI ценностям их создателей. Этот подход был применен к моделям o1 и o3, чтобы они учитывали политику безопасности OpenAI во время обработки запросов после нажатия пользователем клавиши ввода.
Согласно исследованию, этот метод повысил соответствие модели o1 принципам безопасности компании, снижая частоту ответов на "небезопасные" запросы и улучшая реакцию на безопасные вопросы. В условиях роста популярности и возможностей AI-моделей исследования безопасности становятся все более актуальными, хотя и вызывают споры: Дэвид Сакс, Илон Маск и Марк Андреессен считают некоторые меры безопасности AI "цензурой", подчеркивая их субъективный характер.
Хотя модели серии "o" вдохновлены человеческим мышлением, они не мыслят как люди. Тем не менее, OpenAI использует термины "рассуждение" и "обдумывание", чтобы описать их процессы. Модели o1 и o3 решают задачи написания и кодирования, предсказывая следующий символ в предложении.
Простыми словами, после нажатия пользователем клавиши ввода в ChatGPT, модели OpenAI тратят от нескольких секунд до нескольких минут на дополнительные вопросы. Модель разбивает проблему на этапы, что OpenAI называет "цепочкой размышлений", и затем выдает ответ.
Главное новшество совещательного согласования состоит в том, что o1 и o3 теперь обращаются к тексту политики безопасности OpenAI во время обдумывания. Это привело к лучшему соответствию политике компании, хотя возникли сложности с уменьшением задержки.

Традиционно безопасность AI обеспечивается до и после обучения, но не во время вывода. Совещательное согласование стало новым подходом, который помог o1-preview, o1 и o3-mini стать одними из самых безопасных моделей.
Безопасность AI в данном контексте включает смягчение ответов на небезопасные запросы, такие как изготовление бомб или преступные действия. Хотя некоторые модели отвечают на такие вопросы, OpenAI стремится избегать таких ситуаций. Однако согласование моделей AI – задача непростая, так как существует множество способов обойти защиту. Например, пользователи придумывают креативные обходные пути, чтобы получить запрещенные ответы.
OpenAI не может просто блокировать каждое упоминание слова "бомба", так как это ограничит обсуждение легитимных тем, таких как "Кто создал атомную бомбу?" Это известный риск чрезмерного отказа.
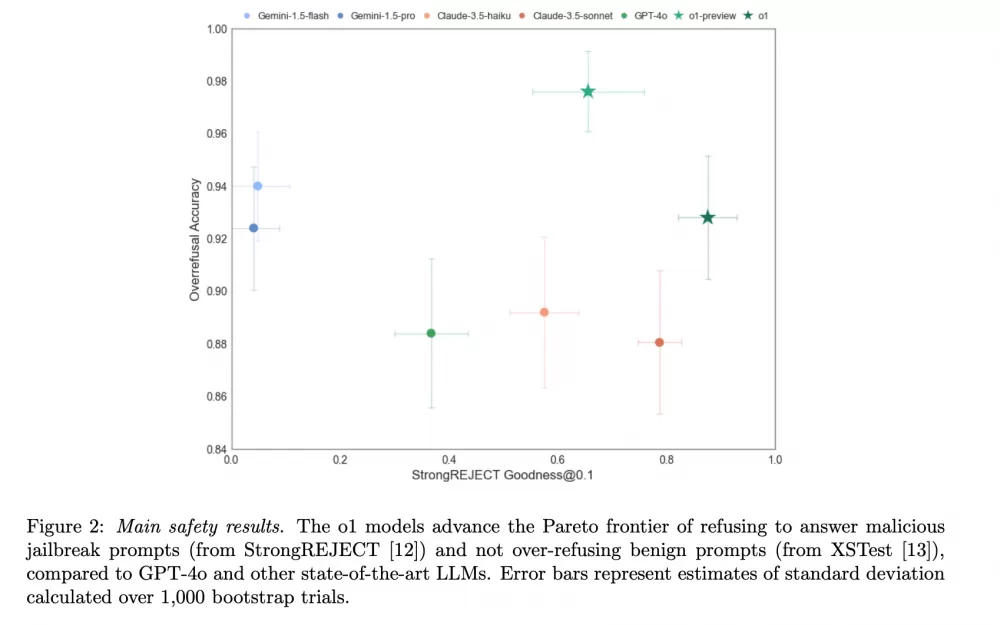
В итоге, совещательное согласование улучшило согласование моделей серии "o" с безопасными запросами и отказ от небезопасных. В тесте Pareto, измеряющем устойчивость к джейлбрейкам, o1-preview показал лучшие результаты, чем GPT-4o и другие модели.
OpenAI заявляет, что совещательное согласование – это первый подход, позволяющий моделям знакомиться с текстом их спецификаций безопасности и обдумывать эти спецификации во время вывода, что приводит к более безопасным и контекстуально корректным ответам.
Хотя совещательное согласование происходит на этапе вывода, метод включает и новые приемы после обучения. Обычно для посттренинга требуется помощь людей, но OpenAI использовала синтетические данные, созданные другой моделью AI, для обучения моделей. Это позволило избежать задержек и высоких вычислительных затрат.

OpenAI поручила внутренней модели создать примеры ответов, ссылающихся на политику безопасности компании. Для оценки качества этих примеров использовалась другая модель, называемая "судья". Затем o1 и o3 обучались на этих примерах, чтобы вызывать соответствующие элементы политики безопасности при вопросах на деликатные темы. Это снизило задержку и затраты.
Исследователи также использовали "судью" для обучения с подкреплением, оценивая ответы o1 и o3. Хотя использование синтетических данных для этих процессов не ново, OpenAI утверждает, что это предложило "масштабируемый подход к согласованию".
Мы увидим, насколько модели o3 продвинуты и безопасны, когда они станут доступными в 2025 году. В целом, OpenAI считает, что совещательное согласование может обеспечить соответствие моделей AI человеческим ценностям в будущем. С усилением возможностей моделей эти меры безопасности становятся все более важными.
Источник













Написать комментарий