
Tencent представила Hunyuan-Large — крупнейшую открытую модель с 389 миллиардами параметров
Недавно вышедшая Hunyuan-Large от Tencent, кажется, немного прошла мимо внимания широкой аудитории, а ведь это по-настоящему значимое событие в мире ИИ. На первый взгляд — очередная модель, но на деле — это крупнейшая открытая MoE модель на основе Transformer с впечатляющими 389 миллиардами параметров и 52 миллиардами активных параметров! Давайте разберёмся, почему это настолько важно и чем Hunyuan-Large может удивить даже искушённых специалистов.
Основные достоинства модели:
Возможность обработки супер-длинных контекстов — поддержка текстов до 256 тысяч токенов. Это значит, что модель может легко справляться с массивными документами, сохраняя связность и внимание к деталям даже в самых длинных текстах.
Эффективность использования памяти — Hunyuan-Large задействует инновационные методы, такие как сжатие кеша и адаптивные уровни обучения для «экспертов», что позволяет снижать нагрузку на ресурсы и поддерживать высокую производительность.
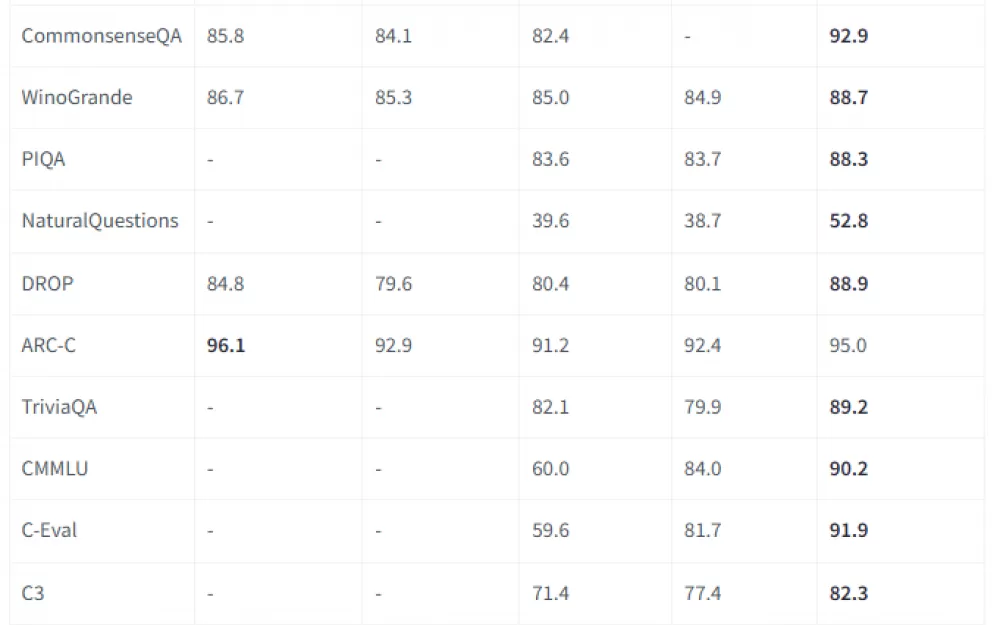
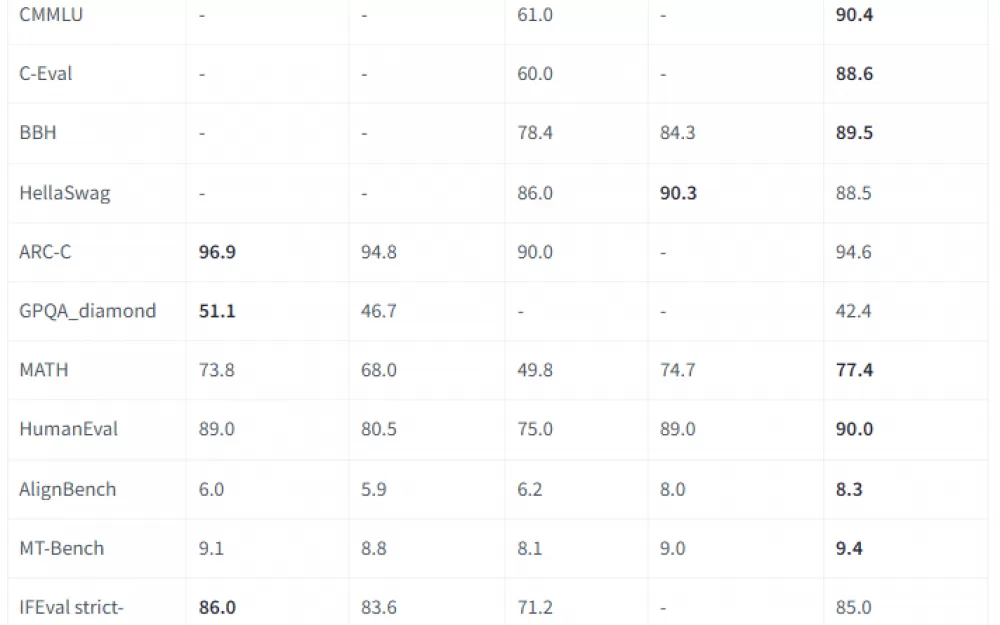
Точность на уровне лучших — модель уверенно показывает себя на бенчмарках вроде MMLU, CMMLU и других. Она не просто конкурирует, но и превосходит ряд известных моделей в задачах на понимание и анализ текста.
Итак, если вы ещё не обратили внимание на эту модель — самое время присмотреться! Tencent открывает доступ к Hunyuan-Large, приглашая исследователей и разработчиков к сотрудничеству и совместной работе над расширением границ искусственного интеллекта. Ну и ждем 32b, 14b и 7b версии!
На Huggingface имеются:
1. Демо-версия
2. Претренерованная модель на 800гб: Hunyuan-Large pre-trained model
3. Инструкт модель на 800гб: Hunyuan-Large-Instruct
4. Инструкт модель на 400гб: Hunyuan-Large-Instruct-FP8
Пара бенчмарков:
Hunyuan-Large pre-trained model
Hunyuan-Large-Instruct













Написать комментарий