
Большой прорыв в понимании работы LLM — Anthropic опубликовала исследование
Обычно модели AI воспринимаются как черный ящик, где ввод данных приводит к выводу ответа, но неясно, почему модель выбрала именно этот ответ.
Заглянуть внутрь "черного ящика" это не решение, поскольку внутреннее состояние модели состоит из длинного списка чисел (активации нейронов), которые трудно интерпретировать.

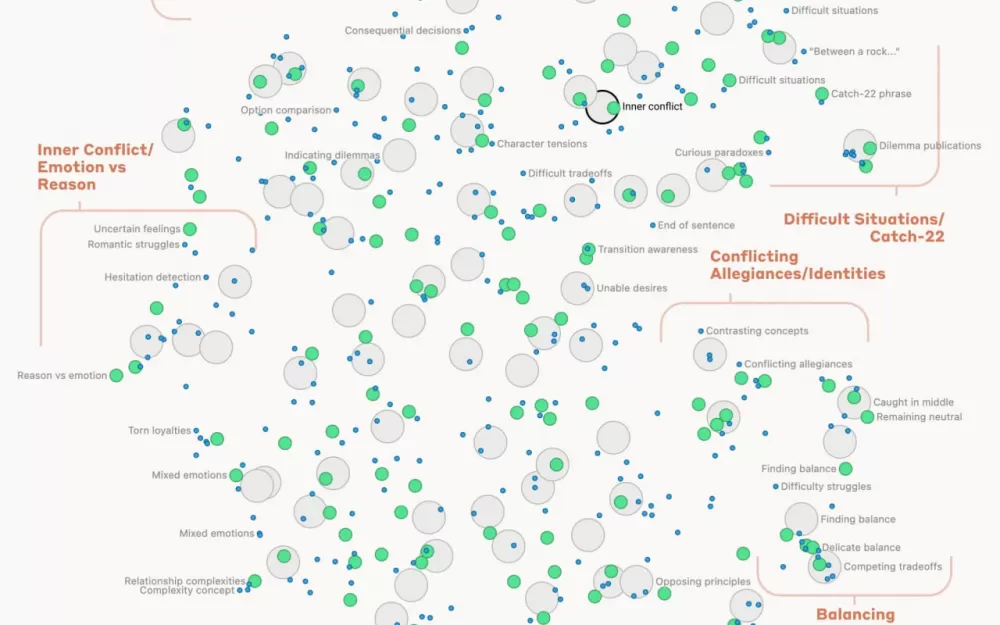
Однако, благодаря применению техники "обучения словаря", сотрудники Anthropic смогли сопоставить паттерны активации нейронов с понятными человеку концепциями, это позволяет ю представлять любое состояния модели через несколько активных признаков вместо множества активных нейронов.
В октябре 2023 года было успешно применено обучение словаря к небольшой "игрушечной" языковой модели.

Эта работа была расширена до больших и сложных моделей, включая Claude Sonnet, что позволило выявить миллионы признаков, отражающих широкий спектр сущностей, таких как города, люди, элементы, научные области и синтаксис языков программирования. Эти признаки могут быть мультимодальными и многоязычными.
Авторы также обнаружили возможность манипулировать этими признаками, усиливая их для изменения поведения модели. Например, усиление признака "Золотые ворота" привело к тому, что модель начала ассоциировать себя с мостом, добавляя определение в любую тему разговора.
Работа над улучшением безопасности моделей AI продолжается, и в Anthropic надеются использовать эти открытия для мониторинга систем AI на предмет нежелательного поведения, для направления их к желаемым результатам или удаления опасных тем.
📎 Научная статья от Anthropic
Если интересуетесь машинным обучением и LLM, здесь я публикую разбор свежих моделей, статей и гайдов, кладешь полезной информации, заходите в гости.













Написать комментарий