Universal-1 от AssemblyAI превзошел Whisper от OpenAI: новый лидер в гонке решений для распознавания речи
Почти год Whisper от OpenAI удерживал лидерство среди открытых решений для распознавания речи, но теперь пальму первенства среди API сервисов перехватила новая модель Universal-1 от AssemblyAI. Обученная на более чем 12,5 миллионах часов многоязычных аудиоданных, Universal-1 превосходит предыдущего лидера - Whisper от OpenAI, а также другие коммерческие решения по ключевым параметрам.
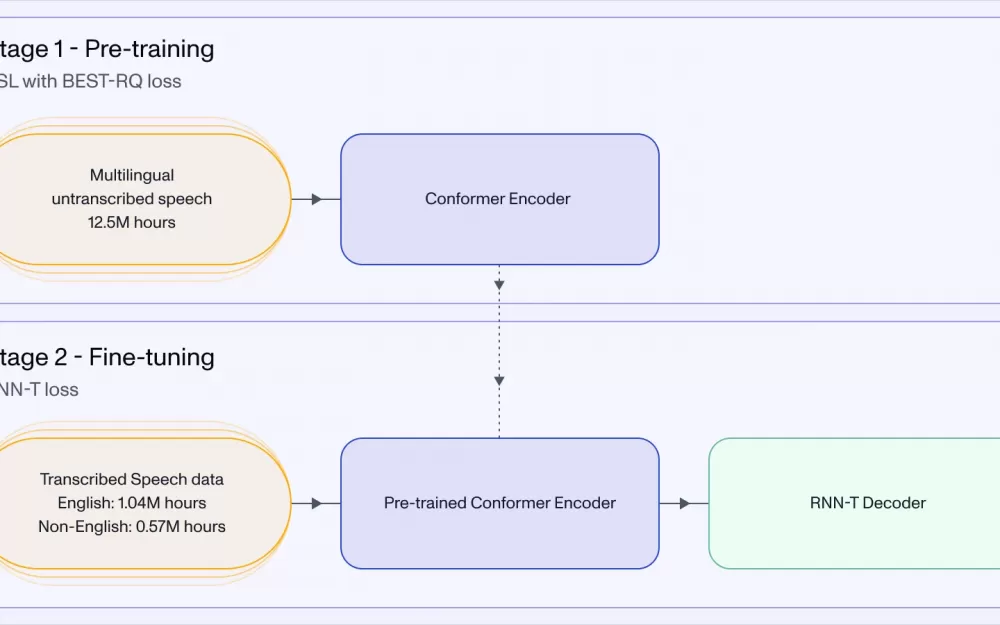
В основе Universal-1 лежит архитектура Conformer RNN-T с 600 миллионами параметров. Энкодер модели состоит из стека сверточных слоев для 4-кратного субдискретизации, позиционного кодирования и 24 слоев Conformer, использующих chunk-wise attention с размером чанка 8 секунд. Это обеспечивает не только устойчивость к вариациям длительности аудио, но и ускоряет обработку за счет ограничения вычислений внимания внутри каждого чанка. Декодер RNN-T использует двухслойный LSTM предиктор и джойнер для генерации выходных токенов.
Процесс обучения Universal-1 состоял из двух этапов: предобучения энкодера на немаркированных аудиоданных с помощью алгоритма BEST-RQ и дообучения полной модели RNN-T на маркированных данных. Для предобучения использовался оптимизатор AdamW с линейно убывающей скоростью обучения, а дообучение проводилось с различными скоростями обучения для энкодера и декодера. Использование микса из транскрибированных человеком и псевдомаркированных данных позволило добиться высокой акустической и лингвистической устойчивости модели.
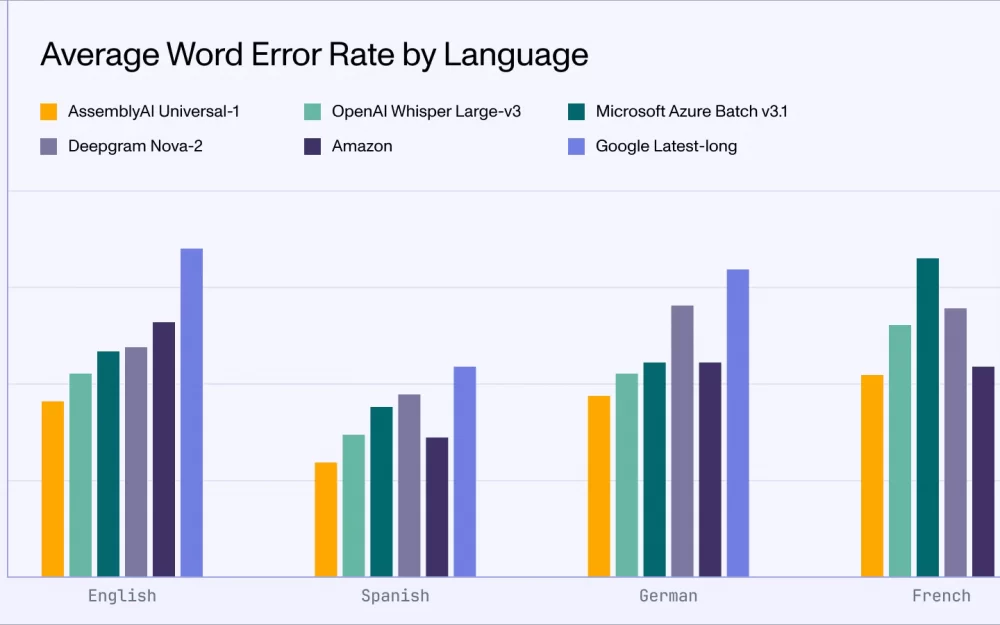
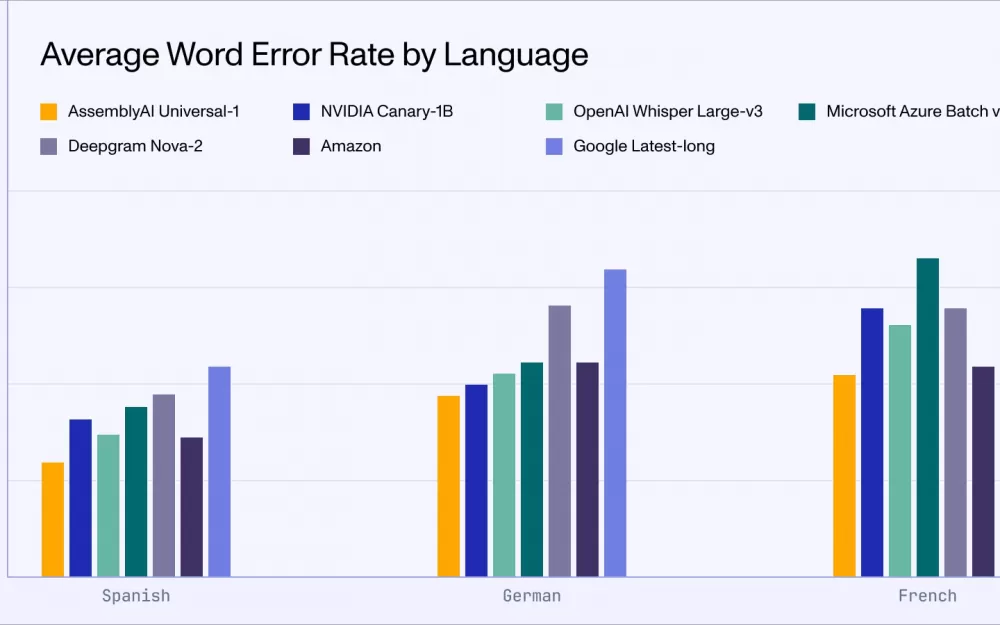
Результаты тестирования показывают, что Universal-1 превосходит аналоги по точности распознавания речи на 10% и более для английского, испанского и немецкого языков, а также генерирует на 30% меньше некорректных вставок слов на обычной речи и на 90% - на фоновых шумах. Universal-1 демонстрирует WER на уровне 7.3% для английского языка на разнообразных тестовых датасетах, опережая такие модели как Whisper Large-v3 и решения от Google, Amazon, Microsoft и Deepgram.
Помимо качества, Universal-1 отличается высокой скоростью работы благодаря оптимизированной архитектуре и распараллеливанию инференса. Модель обрабатывает 1 час аудио всего за 38 секунд на одном GPU, что в 5 раз быстрее оптимизированной реализации Whisper Large-v3 на том же оборудовании.
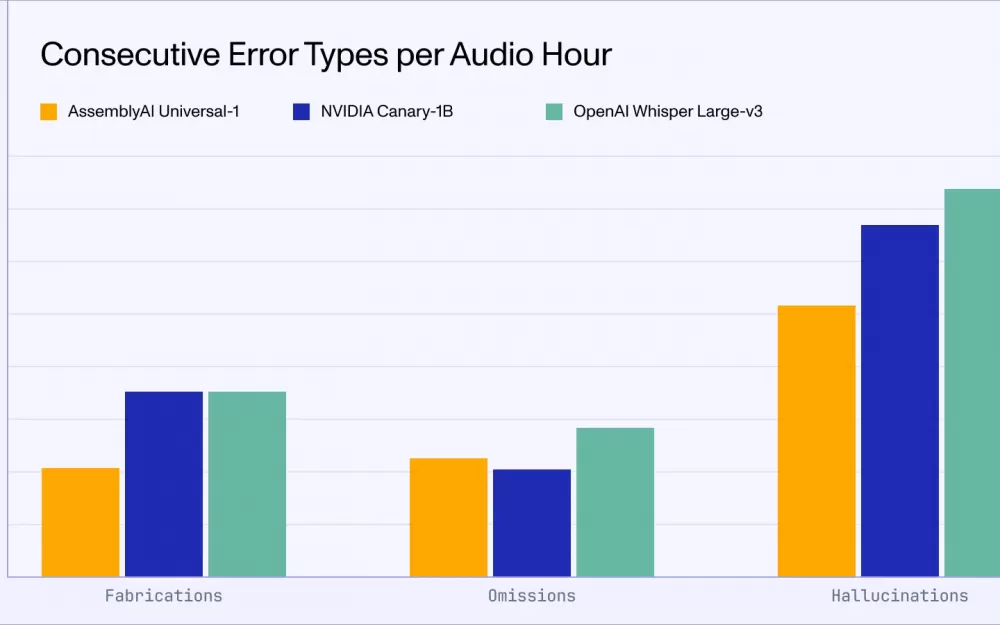
Universal-1 также показывает улучшенную на 13% точность оценки временных меток слов по сравнению с Conformer-2 и на 26% - с Whisper Large-v3. Это позволило повысить качество диаризации дикторов, снизив ошибку cpWER на 14% и увеличив точность подсчета количества дикторов на 71%.
Еще одно важное преимущество Universal-1 - многоязычность. Модель способна распознавать речь на нескольких языках в рамках одного аудиофайла (code-switching). При этом в 71% случаев пользователи предпочитают транскрипции Universal-1 по сравнению с предыдущей моделью Conformer-2.
Модель уже доступна клиентам AssemblyAI через API. Учитывая значительный технологический прогресс, достигнутый в новой модели, AssemblyAI имеет все шансы потеснить таких гигантов как OpenAI, Google, Amazon и Microsoft на быстрорастущем рынке решений для распознавания речи.
Universal-1 открывает новые возможности для разработчиков и бизнеса, нуждающихся в высококачественных и быстрых инструментах для транскрибирования и анализа аудиоданных.
По сообщениям тех, кто уже успел попробовать его в деле, к тестированию доступны бесплатные 100 часов. Так что попробуйте протестировать и вы!:)
Спасибо за прочтение!













Написать комментарий