
Microsoft Research разработала новый способ включения знаний в LLM
Microsoft Research разработала более эффективный способ включения внешних знаний в языковые модели. Новая система, называемая Knowledge Base-Augmented Language Models , использует подход plug-and-play, который не требует изменения существующих моделей.
В отличие от современных подходов, таких как RAG или In-Context Learning, KBLaM не использует отдельные системы поиска. Вместо этого он превращает знания в векторные пары и вплетает их непосредственно в архитектуру модели, используя то, что Microsoft называет «прямоугольным вниманием».
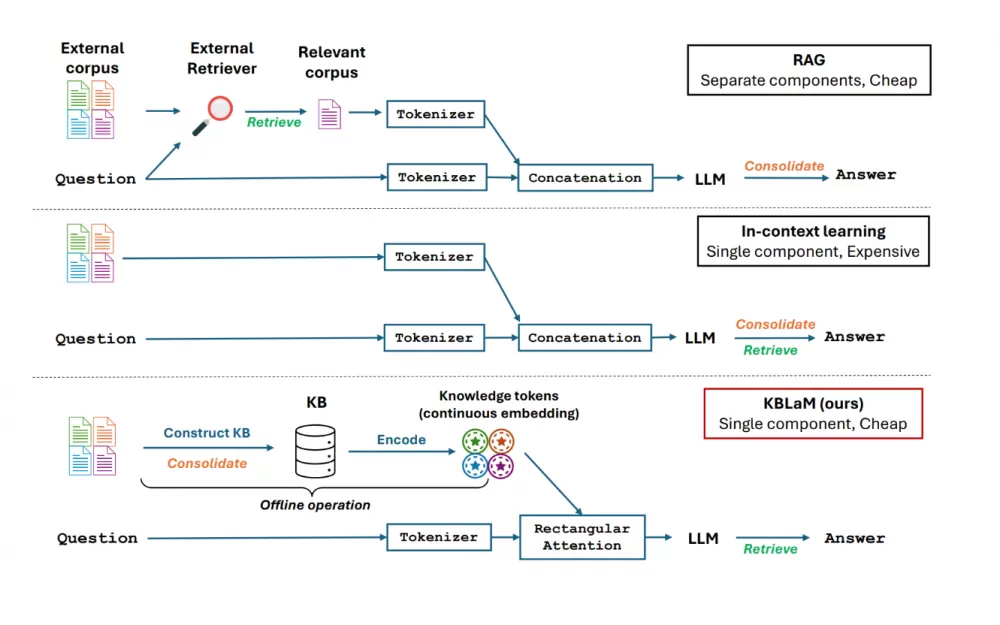
Текущие системы RAG сталкиваются с проблемой квадратичного масштабирования из-за своего механизма самовнимания — каждый токен должен взаимодействовать с каждым другим токеном. Когда 1000 токенов из базы знаний вставляются в контекст, модель должна обработать один миллион пар токенов. При 10 000 токенов это увеличивается до 100 миллионов взаимодействий.
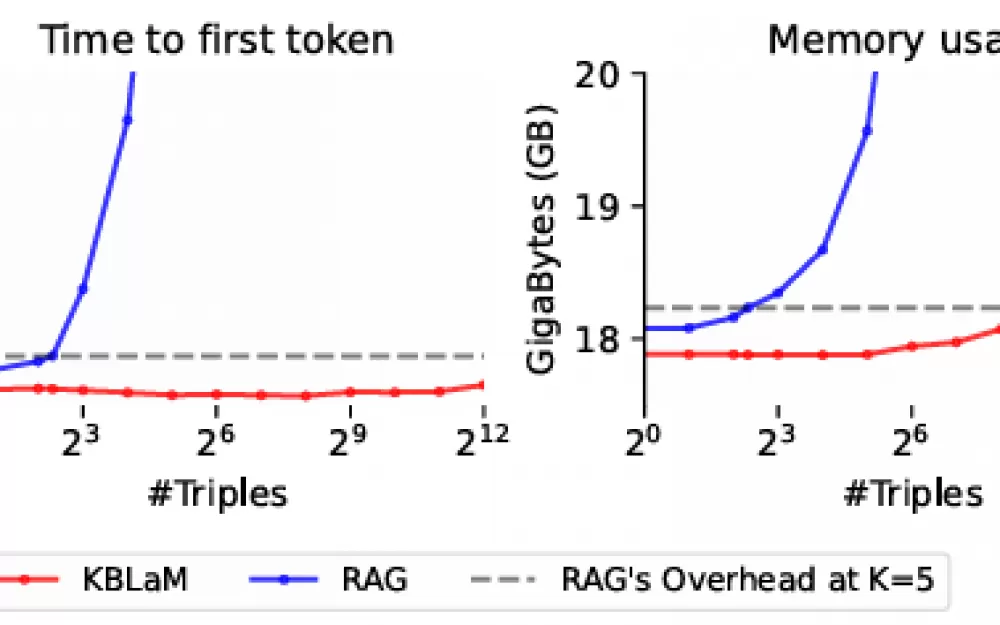
KBLaM обходит эту проблему: хотя ввод пользователя может получить доступ ко всем токенам знаний, эти токены знаний не взаимодействуют друг с другом или с вводом. Это означает, что по мере роста базы знаний требуемая вычислительная мощность увеличивается только линейно. По словам исследователей, один графический процессор может обрабатывать более 10 000 троек знаний (около 200 000 токенов).
Тесты показывают многообещающие результаты. Работая примерно с 200 элементами знаний, KBLaM лучше традиционных моделей избегает галлюцинаций и отказывается отвечать на вопросы, по которым у него нет информации. Он также более прозрачен, чем контекстное обучение, поскольку может связывать знания с конкретными токенами.
Код и наборы данных для KBLaM теперь доступны на GitHub. Система работает с несколькими популярными моделями, включая Llama 3 от Meta и Phi-3 от Microsoft, с планами добавить поддержку Hugging Face Transformers. Исследователи подчеркивают, что KBLaM пока не готов к широкому использованию. Хотя он хорошо справляется с простыми вопросами и ответами, ему все еще нужно поработать над более сложными задачами рассуждения.
LLM сталкиваются с интересным парадоксом: их контекстные окна продолжают расти, позволяя им обрабатывать больше информации одновременно, но надежная обработка всех этих данных остается проблемой. В результате RAG стал основным решением для подачи определенной информации в модели с относительной надежностью, но KBLaM предполагает, что может быть более эффективный путь вперед.
Источник












Написать комментарий