
Factorio пополняет список видеоигр, которые также тестируют производительность AI
Factorio, сложная компьютерная игра, ориентированная на строительство и управление ресурсами, стала последним инструментом исследователей для оценки возможностей AI. Игра проверяет способность языковых моделей планировать и строить сложные системы, управляя при этом множеством ресурсов и производственных цепочек.
Factorio Learning Environment (FLE) предоставляет два различных режима тестирования. «Lab-Play» включает 24 структурированных задания с определенными целями и ограниченными ресурсами, от простых сборок из двух машин до сложных фабрик с почти 100 машинами. В режиме «Open Play» агенты AI исследуют процедурно сгенерированные карты с одной целью: построить самую большую возможную фабрику.
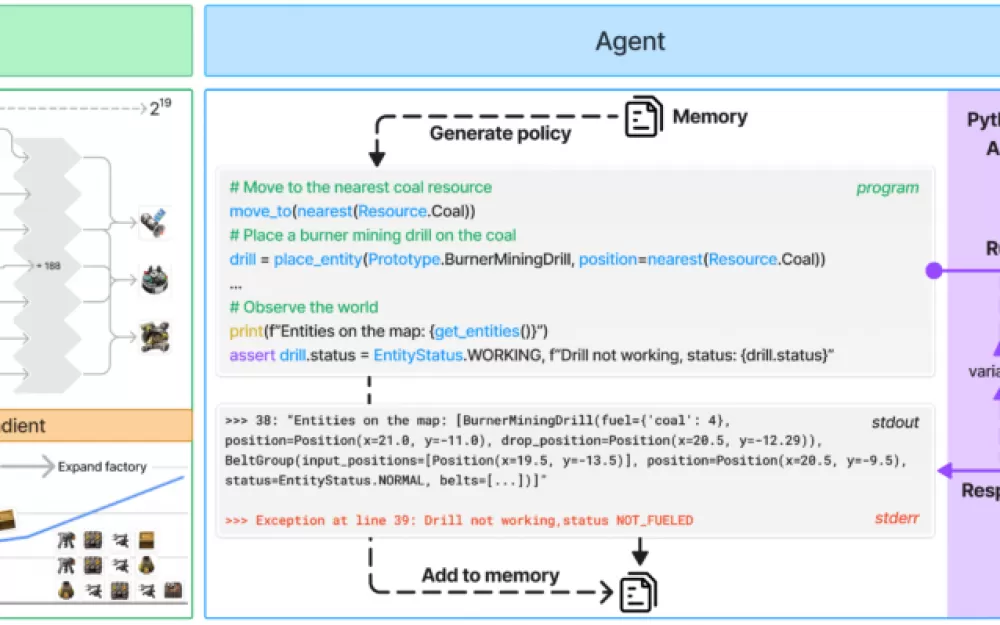
Система работает через API Python, который позволяет агентам генерировать код для действий и проверять статус игры. Эта настройка проверяет способность языковых моделей синтезировать программы и управлять сложными системами. API обеспечивает функции для размещения и соединения компонентов, управления ресурсами и мониторинга хода производства.
Для измерения успеха исследователи оценивают производительность агентов, используя два ключевых измерения: «Производственный показатель», который вычисляет общую стоимость продукции и увеличивается экспоненциально с ростом сложности производственной цепочки, и «Вехи», которые отслеживают важные достижения, такие как создание новых предметов или исследование технологий. Экономическая симуляция игры учитывает такие факторы, как дефицит ресурсов, рыночные цены и эффективность производства.
Исследовательская группа, в которую входит ученый Anthropic, оценила шесть ведущих языковых моделей в среде FLE: Claude 3.5 Sonnet, GPT-4o и GPT-4o mini, DeepSeek-V3, Gemini 2.0 Flash и Llama-3.3-70B-Instruct. Большие модели рассуждений (LRM) не были включены в этот раунд тестирования, хотя предыдущие тесты показывают, что такие модели, как o1, демонстрируют превосходные возможности планирования, несмотря на их собственные ограничения.
Тестирование выявило существенные проблемы для оцениваемых языковых моделей, особенно с пространственным мышлением, долгосрочным планированием и исправлением ошибок. При строительстве фабрик агенты AI испытывали трудности с эффективной расстановкой и подключением машин, что приводило к неоптимальным макетам и узким местам в производстве.
Стратегическое мышление также оказалось сложным. Модели последовательно отдавали приоритет краткосрочным целям, а не долгосрочному планированию. И хотя они могли справиться с базовым устранением неполадок, они часто спотыкались, сталкиваясь с более сложными проблемами, и попадали в ловушку неэффективных циклов отладки.
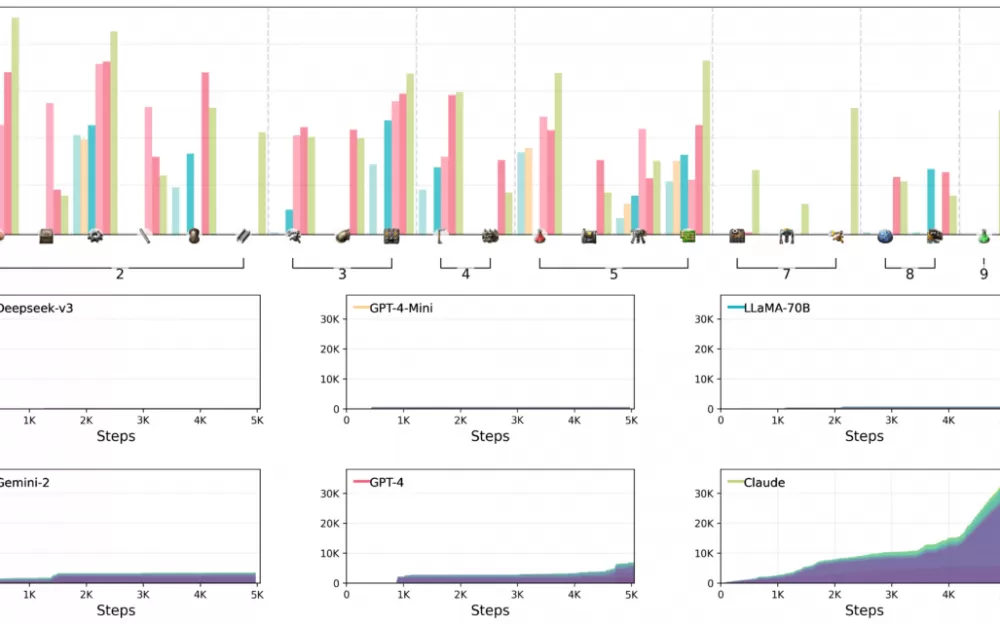
Среди протестированных моделей Claude 3.5 Sonnet показала самую высокую производительность, хотя и не смогла справиться со всеми задачами. В режиме Lab Play Claude успешно выполнил 15 из 24 задач, в то время как конкурирующие модели решили не более 10. Во время тестирования Open Play Claude достигла производственного балла в 2456 баллов, а GPT-4o набрала 1789 баллов.
Claude продемонстрировал сложный игровой процесс Factorio с помощью стратегического подхода к производству и исследованиям. В то время как другие модели оставались сосредоточенными на базовых продуктах, Claude быстро перешел к сложным производственным процессам. Ярким примером стал переход на технологию электродрели, что привело к существенному увеличению темпов производства железных пластин.
Исследователи предполагают, что открытая, масштабируемая природа FLE делает его ценным для тестирования будущих, потенциально более эффективных языковых моделей. Они отмечают, что модели рассуждений еще не были оценены, и предлагают расширить среду, включив в нее многоагентные сценарии и контрольные показатели человеческой производительности для лучшего контекста.
Эта работа пополняет растущую коллекцию игровых бенчмарков AI, включая коллекцию BALROG и предстоящий MCBench, который будет тестировать модели с использованием зданий Minecraft. Предыдущие вехи игрового AI включают системы OpenAI, которые победили профессиональные человеческие команды.
Источник












Написать комментарий