
Модели AI на «экзамене» по решению головоломок: исследование выявило неожиданные результаты
Каждое воскресенье ведущий NPR Уилл Шортц, гуру кроссвордов из The New York Times, проводит викторину для тысяч слушателей в рамках долгоиграющего сегмента под названием «Воскресная головоломка». Несмотря на то, что головоломки составлены так, чтобы их можно было решить, не слишком полагаясь на знания, они обычно сложны даже для опытных участников.
Вот почему некоторые эксперты считают, что это многообещающий способ проверить границы возможностей AI в решении задач.
В недавнем исследовании команда учёных из Колледжа Уэллсли, Оберлинского колледжа, Техасского университета в Остине, Северо-Восточного университета, Карлова университета и стартапа Cursor создала тест для AI, используя загадки из выпусков «Воскресной головоломки». Команда говорит, что их тест выявил неожиданные факты, например, что модели рассуждений — в том числе o1 от OpenAI — иногда «сдаются» и дают ответы, которые, как они знают, неверны.
«Мы хотели разработать эталонный тест с задачами, которые люди могут понять, обладая лишь общими знаниями», — рассказал TechCrunch Арджун Гуха, преподаватель компьютерных наук в Северо-Восточном университете и один из соавторов исследования.
В настоящее время индустрия AI находится в затруднительном положении, связанном с тестированием. Большинство тестов, которые обычно используются для оценки моделей AI, проверяют такие навыки, как компетентность в вопросах по математике и естественным наукам на уровне доктора наук, которые не имеют отношения к среднестатистическому пользователю. В то же время многие тесты — даже тесты, выпущенные относительно недавно — быстро приближаются к точке насыщения.
Преимущества викторины на общественном радио, такой как «Воскресная головоломка», заключаются в том, что она не требует глубоких знаний, а задания сформулированы таким образом, что модели не могут использовать «механическую память» для их решения, объяснила Гуха.
«Я думаю, что сложность этих задач заключается в том, что очень трудно добиться значимого прогресса в решении проблемы, пока вы её не решите, — вот тогда всё встаёт на свои места, — сказал Гуха. — Это требует сочетания проницательности и процесса исключения».
Конечно, ни один тест не является идеальным. «Воскресная головоломка» ориентирована на США и доступна только на английском языке. А поскольку тесты общедоступны, модели, обученные на них, могут в некотором смысле «обманывать», хотя Гуха говорит, что не видел доказательств этого.
«Каждую неделю появляются новые вопросы, и мы можем ожидать, что последние вопросы действительно будут уникальными, — добавил он. — Мы намерены обновлять тест и отслеживать, как со временем меняется производительность модели».
В тесте, составленном исследователями и включающем около 600 загадок из «Воскресной головоломки», модели логического мышления, такие как o1 и R1 от DeepSeek, значительно превосходят остальные. Модели логического мышления тщательно проверяют факты, прежде чем выдавать результаты, что помогает им избегать некоторых ошибок, которые обычно приводят к сбоям в моделях AI. Недостатком является то, что моделям логического мышления требуется немного больше времени для поиска решений — обычно от нескольких секунд до нескольких минут.
По крайней мере одна модель, R1 от DeepSeek, предлагает решения, которые, как она знает, являются неправильными для некоторых вопросов «Воскресной головоломки». R1 буквально говорит: «Я сдаюсь», а затем даёт неверный ответ, который кажется случайным, — поведение, с которым человек определённо может себя ассоциировать.
Модели делают и другие странные выборы, например, дают неправильный ответ, а затем сразу же отказываются от него, пытаются найти более подходящий вариант и снова терпят неудачу. Они также бесконечно «размышляют» и дают бессмысленные объяснения ответов, или сразу же находят правильный ответ, но затем без видимой причины переходят к рассмотрению альтернативных вариантов.
«При решении сложных задач R1 буквально говорит, что он «разочарован», — сказал Гуха. — Забавно было наблюдать, как модель имитирует то, что мог бы сказать человек. Пока неясно, как «разочарование» в рассуждениях может повлиять на качество результатов модели».

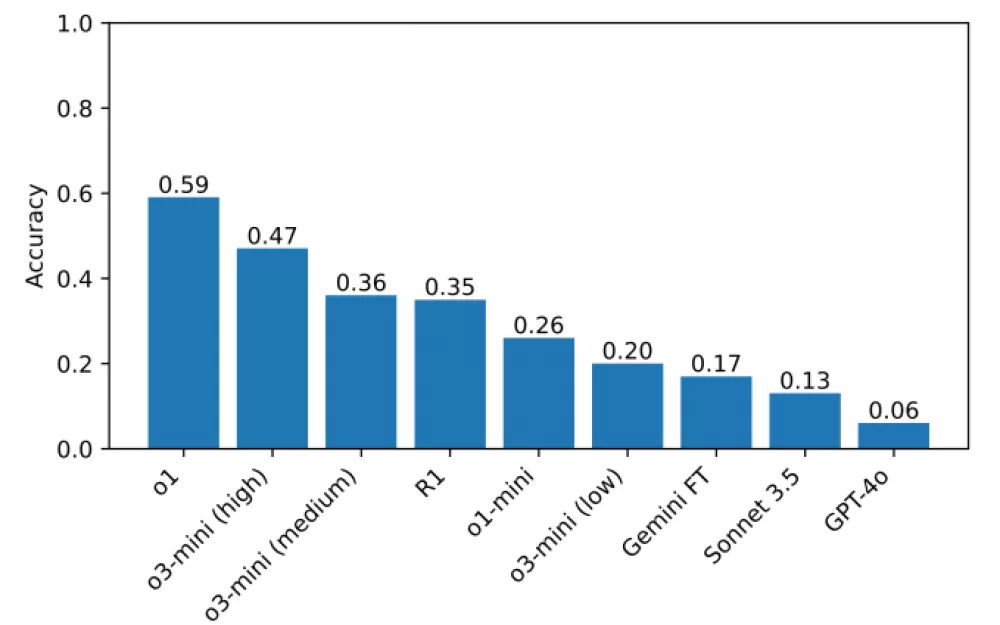
На данный момент лучшей моделью в этом бенчмарке является o1 с результатом 59%, за ней следует недавно выпущенная o3-mini с высоким показателем «усилий по рассуждению» (47%). (R1 набрала 35%). В качестве следующего шага исследователи планируют расширить тестирование на дополнительные модели рассуждений, что, как они надеются, поможет выявить области, в которых эти модели можно улучшить.
«Чтобы хорошо рассуждать, не обязательно иметь докторскую степень, поэтому можно разработать тесты для оценки рассуждений, которые не требуют знаний на этом уровне, — сказал Гуха. — Тест с более широким доступом позволяет большему числу исследователей понимать и анализировать результаты, что, в свою очередь, может привести к лучшим решениям в будущем. Кроме того, поскольку современные модели всё чаще используются в сферах, которые затрагивают всех, мы считаем, что каждый должен понимать, на что способны эти модели, а на что нет».
Источник













Написать комментарий