
Как небольшой набор данных и управление вычислениями могут улучшить работу языковых моделей
Новый подход показывает, что тщательно подобранные обучающие данные и гибкое управление вычислениями во время тестирования могут помочь AI-моделям более эффективно решать сложные задачи, требующие логического мышления.
Из почти 60 000 пар вопросов и ответов исследователи выбрали всего 1000 высококачественных примеров, которые соответствовали трём ключевым критериям: они должны были быть сложными, относиться к разным областям знаний и соответствовать высоким стандартам ясности и форматирования. Примеры включали этапы мышления, сгенерированные с помощью Gemini 2.0 Flash Thinking.
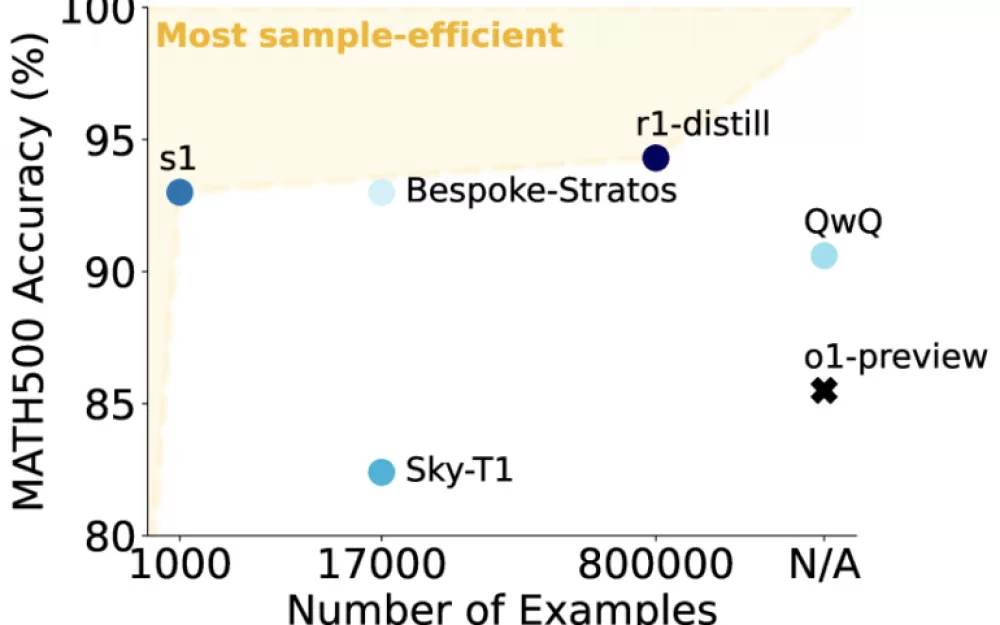
Используя этот компактный, но тщательно подобранный набор данных, исследователи из Стэнфордского университета и Института искусственного интеллекта Аллена обучили языковую модель среднего размера под названием s1-32B на основе Qwen2.5 с 32 миллиардами параметров.
Модель изучила по примерам решений, какие шаги и объяснения приводят к правильным ответам. Благодаря целенаправленному отбору данных обучение заняло всего 26 минут на 16 графических процессорах Nvidia H100 — в общей сложности около 25 часов работы на графическом процессоре. Хотя точные цифры для аналогичных моделей, таких как OpenAI o1 или DeepSeek-R1, неизвестны, они, вероятно, требуют тысяч часов работы на графическом процессоре.
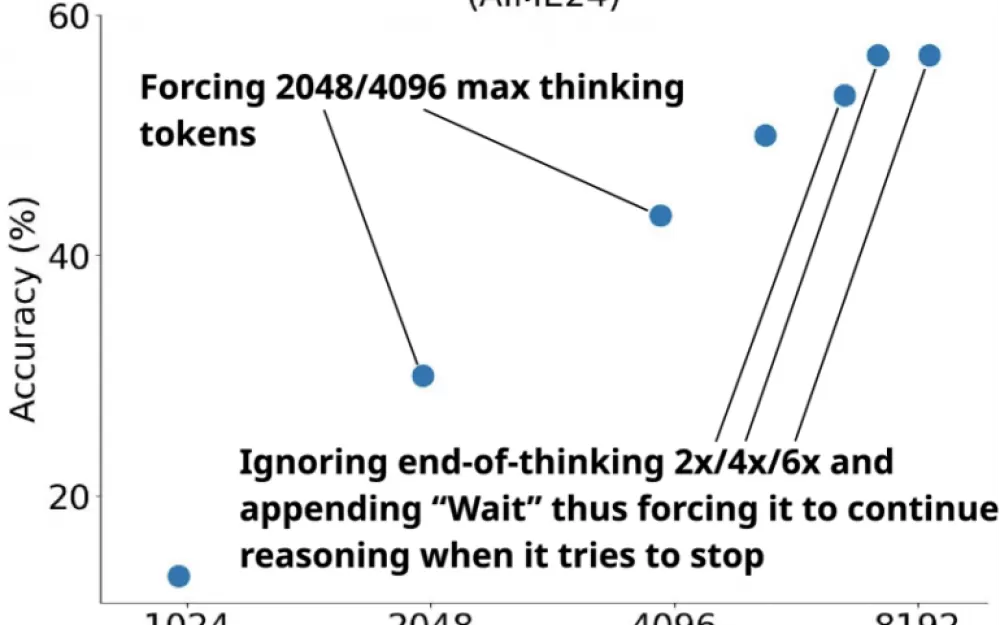
Команда также разработала «бюджетное принуждение» — метод контроля мыслительного процесса модели. Если модель выполняет заданное количество шагов вычислений, она должна выдать ответ. Если модели требуется больше времени, добавление слова «Подождите» побуждает её пересмотреть предыдущий ответ и проверить свои рассуждения на наличие ошибок.

Ограничение бюджета позволяет пользователям при необходимости корректировать тщательность обучения модели. Тесты показали, что более высокий бюджет, вызванный более частыми командами «Подождите», даёт лучшие результаты. Обученная модель даже превзошла более требовательные к данным модели OpenAI o1-preview и o1-mini в математических тестах.
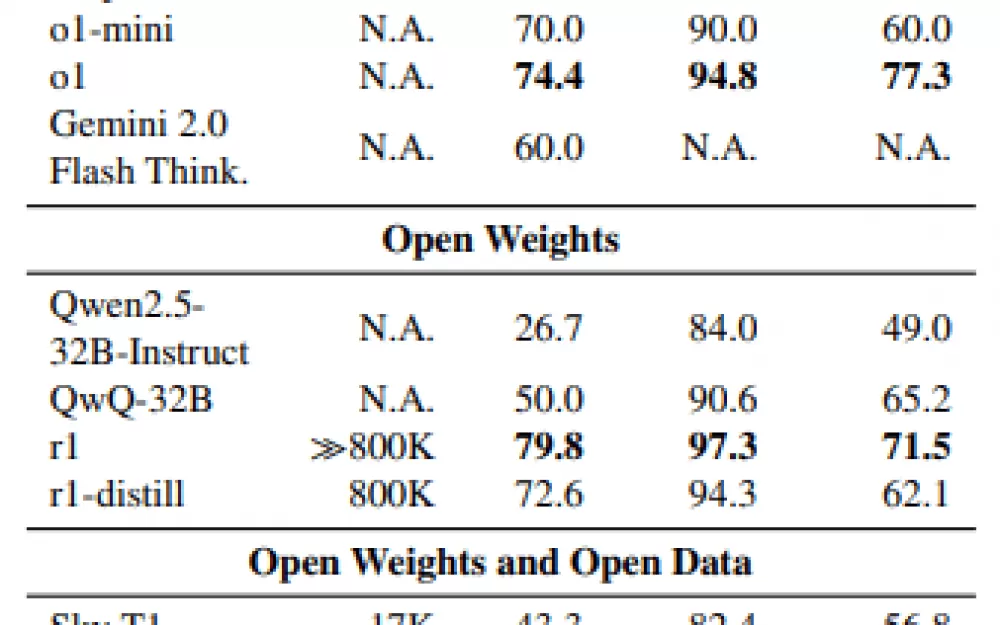
Дальнейшие тесты показали, что только сочетание всех трёх критериев отбора данных — сложности, разнообразия и качества — обеспечивает оптимальную производительность. Ограничение отбора отдельными критериями или случайный выбор приводили к ухудшению результатов на 30 процентов.
Интересно, что даже полный набор данных, в 59 раз превышающий по объёму тщательно отобранные 1000 примеров, не улучшил результаты. Контроль бюджета оказался более важным, позволяя точно управлять вычислениями во время тестирования и демонстрируя чёткую связь между вложенными токенами и производительностью.
Исследование показывает, что небольшой, но хорошо подобранный обучающий набор данных может подготовить языковые модели к решению сложных задач. В сочетании с гибкими вычислениями во время тестирования модели могут работать более эффективно, когда это необходимо, без увеличения их размера.
Хотя s1-32B и принудительное распределение бюджета выглядят многообещающе, результаты тестов отражают производительность только в узком наборе навыков. Исследователи поделились своим кодом и данными о тренировках на GitHub, чтобы стимулировать дальнейшее развитие.
Многие исследовательские группы пытались сопоставить ведущие модели искусственного интеллекта в сложных рассуждениях, используя все более большие наборы данных. Недавно OpenAI добавила свою последнюю модель reasoning o3-mini в ChatGPT. Однако китайская компания DeepSeek показала, что конкурентоспособные модели возникают благодаря эффективному использованию ресурсов и реализации хороших идей — одним из них может быть форсирование бюджета.
Источник













Написать комментарий