ByteDance выпустили OmniHuman-1: генерация видео по одной картинке и аудиодорожке
Ссылка на официальный анонс : https://omnihuman-lab.github.io/
Примеры некоторых сгенерированных видосов под катом, но на Хабре не очень удобный плеер, поэтому остальные я выложил в телеге.
Анимация человека, а именно - генерация говорящего человека на основе аудиодорожки за последние годы сильно прокачалась в качестве. Но существующие подходы всё ещё испытывают трудности с масштабированием.
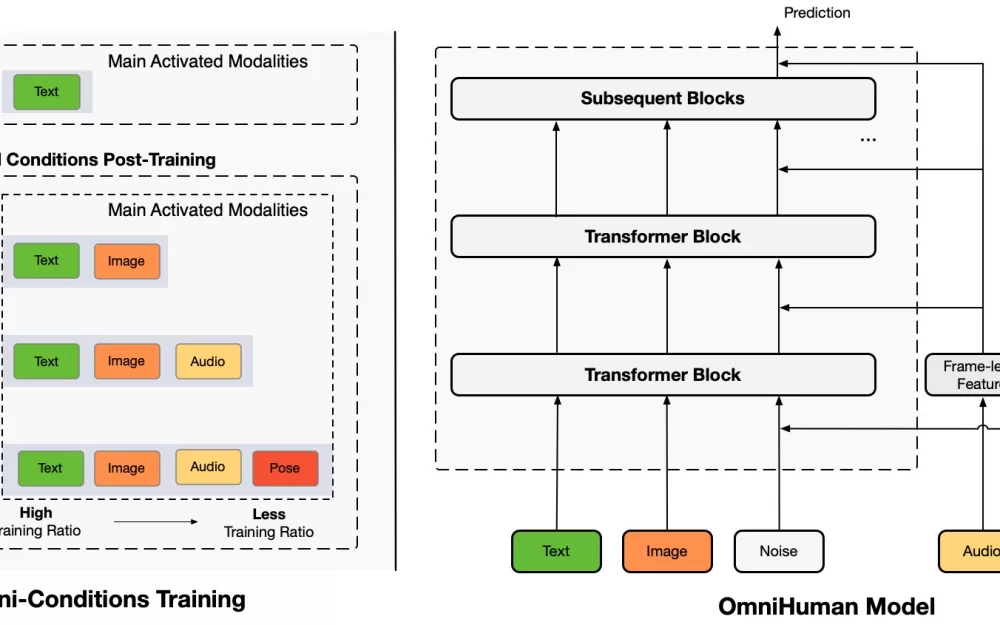
Сегодня ByteDance представили модель OmniHuman — фреймворк на основе Diffusion Transformer, который показывает сильный рост качества за счет, добавления информации о движениях на видео в процесс обучения.
OmniHuman поддерживает различные типы портретного видео (крупный план лица, портрет, по пояс, в полный рост). В качестве аудио подходит как разговорная речь, так и пение, взаимодействие человека с объектами и сложные позы тела, а также различные стили изображений.
В сравнении с существующими методами основанными на аудио, OmniHuman не только создаёт более реалистичные видео, но и обеспечивает большую гибкость во входных данных. Он также поддерживает несколько режимов управления (аудио, видео и комбинированные сигналы).
Да покажи уже видосы
Вот они:
Мой личный фаворит:
Заключение
Когда компании "воюют" технологиями, и гонка между ними - научная, это мне нравится гораздо больше, чем торговые воины прошлых лет между США и Китаем. Наблюдать за конкуренцией OpenAI + Anthropic с одной стороны и DeepSeek + ByteDance с другой с каждым днем все интереснее. На рынке появляется всё больше отличных моделей, и каждые полгода мы вырастаем в качестве почти на порядок. И это прекрасно.
----
P.S. 2025 год на дворе, ну как я могу не бахнуть ссылку на свой Телеграм канал в конце статьи? Я пишу там новости про ИИ раньше всех, регулярно даю глубокую аналитику по отрасли и всем событиям, и рассказываю как создавать собственных агентов и приложения с ИИ. Велком!












Написать комментарий