
AI-модели, такие как Deepseek-R1 и OpenAI o1, страдают от «недомыслия»: как это можно исправить
Китайские исследователи выяснили, почему AI-моделям часто не удаётся справиться со сложными задачами, требующими логического мышления: они склонны слишком быстро отказываться от многообещающих решений, что приводит к напрасной трате вычислительных мощностей и снижению точности.
Исследователи из Tencent AI Lab, Университета Сучжоу и Шанхайского университета Цзяо Тун показывают, что модели-рассуждатели, такие как o1 от OpenAI, часто переключаются между различными подходами к решению задач, часто начиная с нуля, используя такие выражения, как «В качестве альтернативы…». Такое поведение становится более заметным по мере усложнения задач, и модели используют больше вычислительных мощностей, когда приходят к неправильным ответам.

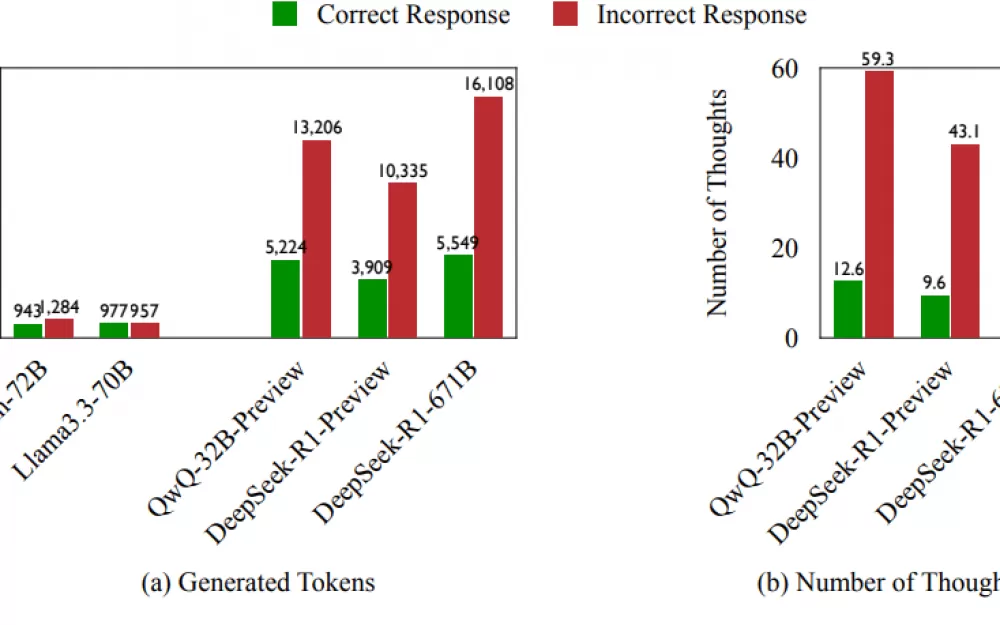
Команда обнаружила, что 70% неверных ответов содержали по крайней мере одну верную логическую цепочку, которая не была полностью изучена. Когда модели давали неверные ответы, они использовали на 225% больше вычислительных токенов и меняли стратегии на 418% чаще, чем при верных ответах.
Чтобы отследить эту проблему, исследователи создали метрику, которая измеряет, насколько эффективно модели используют вычислительные токены, когда дают неправильные ответы. В частности, они смотрели, сколько токенов действительно способствуют поиску правильного решения, прежде чем модель перейдёт к другому подходу.
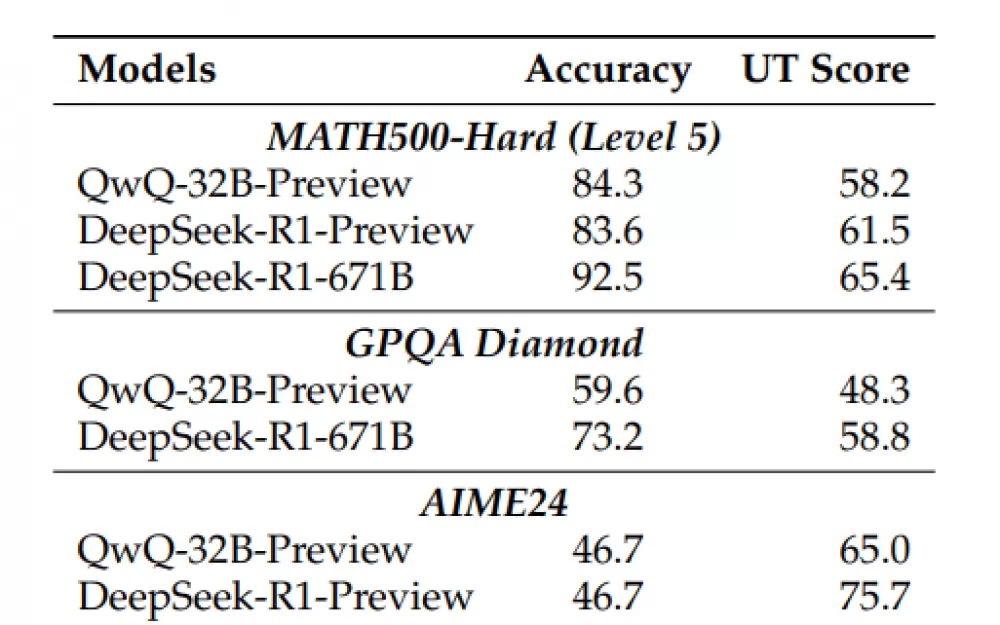
Команда протестировала это на трёх сложных наборах задач: вопросы для математических олимпиад, задачи по физике для студентов и задачи по химии. Они хотели посмотреть, как такие модели, как QwQ-32B-Preview и Deepseek-R1-671B, справляются со сложными рассуждениями. Результаты показали, что модели в стиле o1 часто тратят токены впустую, слишком быстро переключаясь между разными подходами. Удивительно, но модели, которые дают больше правильных ответов, не обязательно используют токены более эффективно.
Чтобы решить проблему недостаточного обдумывания, исследовательская группа разработала так называемый «штраф за переключение мыслей» (TIP). Он работает за счёт корректировки показателей вероятности для определённых токенов — строительных блоков, которые модели используют для формирования ответов.
Когда модель рассматривает возможность использования слов, сигнализирующих об изменении стратегии, например «в качестве альтернативы», TIP наказывает за такой выбор, снижая его вероятность. Это побуждает модель более тщательно исследовать текущую линию рассуждений, прежде чем переходить к другому подходу.
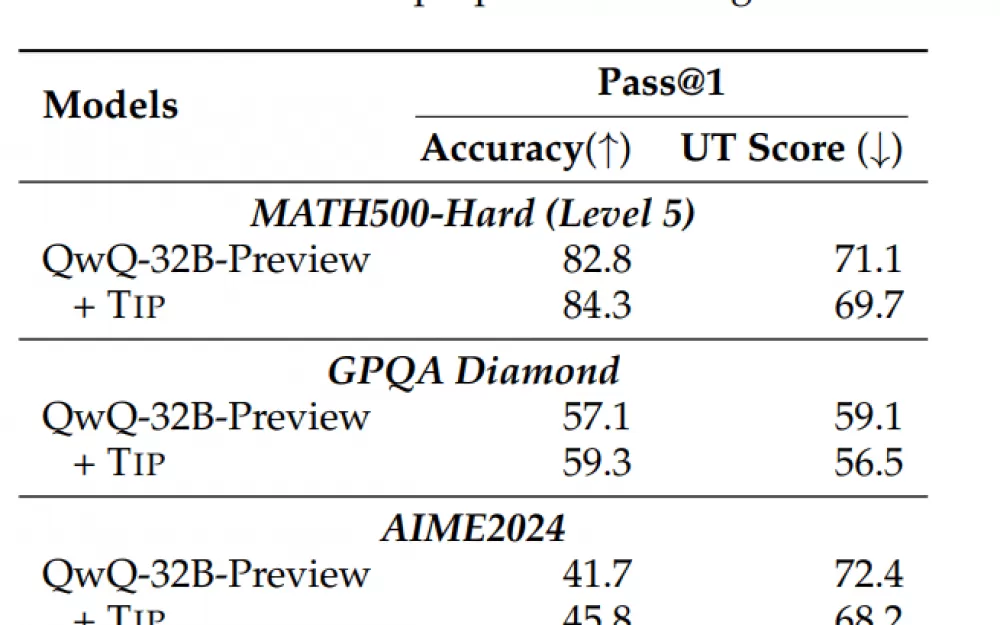
При использовании TIP модель QwQ-32B-Preview правильно решала больше задач MATH500-Hard — точность повысилась с 82,8 до 84,3 процента — и демонстрировала более последовательные рассуждения. Команда наблюдала аналогичные улучшения, когда тестировала модель на других сложных наборах задач, таких как GPQA Diamond и AIME2024.
Эти результаты указывают на кое-что интересное: чтобы AI хорошо рассуждал, ему нужно не только больше вычислительной мощности. Модели также должны научиться определять, когда стоит придерживаться многообещающей идеи. Заглядывая в будущее, исследовательская группа хочет найти способы, с помощью которых модели смогут лучше управлять собственным подходом к решению проблем — понимать, когда стоит продолжать работу над идеей, а когда пора попробовать что-то новое.
Источник













Написать комментарий