Вышел Qwen2.5-VL от Alibaba: распознавание часовых видео, агенты, структурные данные
Астрологи объявили неделю китайских нейросетей. На этот раз у нас апдейт Qwen2.5-VL.
Вышел Qwen2.5-VL от Alibaba
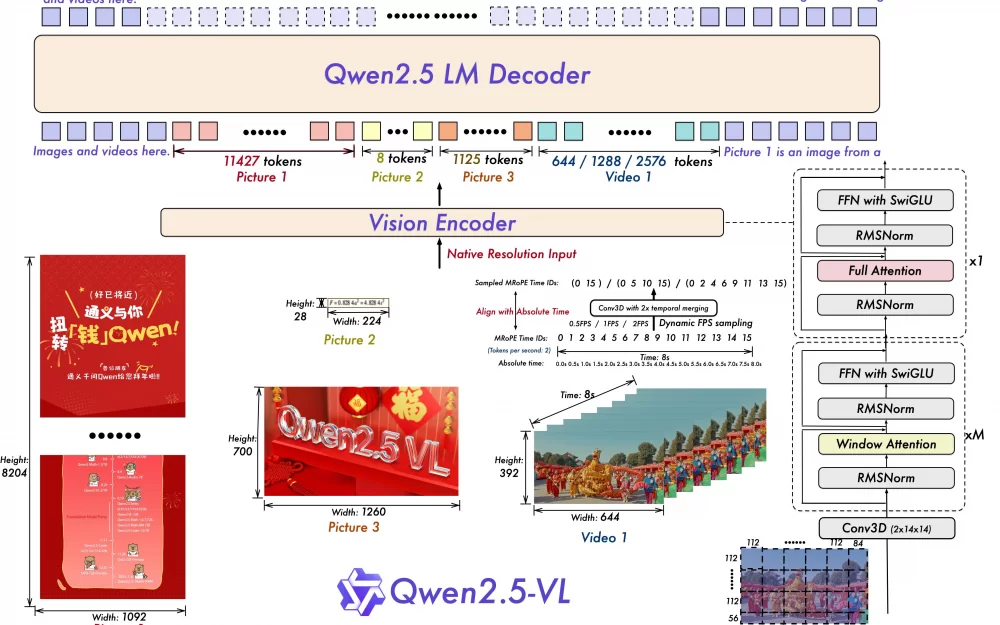
Это модель, умеющая принимать на вход на текст, так и изображения, обладает более развитой способностью "понимать" нарисованное на картинках, в том числе прекрасно справляется с обработкой видео длительности до 1 часа.
Ключевые улучшения
Взято из https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct и переведено на русский с небольшой редактурой для понятности:
Визуальное понимание
Модель Qwen2.5-VL не только умеет распознавать привычные объекты (цветы, птицы, рыбы, насекомые), но и способна анализировать тексты, диаграммы, иконки, графику и макеты внутри изображений.
Работа в формате ИИ-агента:
Qwen2.5-VL может напрямую выступать в роли визуального агента, который умеет рассуждать и динамически использовать различные инструменты, в том числе компьютер или телефон. [Привет, OpenAI Operator!]
Понимание длинных видео и фиксация событий:
Qwen2.5-VL способна разбирать видео длительностью более 1 часа.
Новая возможность — находить конкретные события, выделяя нужные фрагменты видео.
Точная локализация в разных форматах:
Читайте так же:Модель умеет точно находить объекты на изображении, создавая bounding-box или указывая точки.
Она также может выдавать JSON с координатами и характеристиками объектов.
Генерация структурированных данных:
При работе со сканами счетов, форм, таблиц и т.п. Qwen2.5-VL поддерживает структурированный вывод их содержимого, что полезно в финансах, торговле и других сферах.
Обновления архитектуры модели
Динамическое разрешение и частота кадров при обучении видео:
Была расширена идея динамического разрешения, было добавлено временное измерение, и переменная частота кадров (FPS). Это помогает модели понимать видео с разными скоростями воспроизведения.
Также был обновлен mRoPE во временном измерении с помощью использования ID и абсолютной привязки ко времени. Это позволяет модели лучше понимать последовательность событий и скорость, чтобы точнее находить конкретные моменты в видео.
Упрощённый и быстрый визуальный энкодер:
Ускорено обучение и вывод результатов, используя оконное внимание (window attention) в ViT.
Архитектуру ViT оптимизировали с использованием SwiGLU и RMSNorm, чтобы она соответствовала структуре языковой модели Qwen2.5.
Бенчмарки
Тут всё не так однозначно. В каких-то (MathVista_MINI) Qwen2.5-VL уступает моделям от OpenAI, в каких-то лидирует.
Бенчмарки по иозбражений:
Benchmarks | GPT4o | Claude3.5 Sonnet | Gemini-2-flash | InternVL2.5-78B | Qwen2-VL-72B | Qwen2.5-VL-72B |
|---|---|---|---|---|---|---|
MMMUval | 70.3 | 70.4 | 70.7 | 70.1 | 64.5 | 70.2 |
MMMU_Pro | 54.5 | 54.7 | 57.0 | 48.6 | 46.2 | 51.1 |
MathVista_MINI | 63.8 | 65.4 | 73.1 | 76.6 | 70.5 | 74.8 |
MathVision_FULL | 30.4 | 38.3 | 41.3 | 32.2 | 25.9 | 38.1 |
Hallusion Bench | 55.0 | 55.16 | 57.4 | 58.1 | 55.16 | |
MMBench_DEV_EN_V11 | 82.1 | 83.4 | 83.0 | 88.5 | 86.6 | 88 |
AI2D_TEST | 84.6 | 81.2 | 89.1 | 88.1 | 88.4 | |
ChartQA_TEST | 86.7 | 90.8 | 85.2 | 88.3 | 88.3 | 89.5 |
DocVQA_VAL | 91.1 | 95.2 | 92.1 | 96.5 | 96.1 | 96.4 |
MMStar | 64.7 | 65.1 | 69.4 | 69.5 | 68.3 | 70.8 |
MMVet_turbo | 69.1 | 70.1 | 72.3 | 74.0 | 76.19 | |
OCRBench | 736 | 788 | 854 | 877 | 885 | |
OCRBench-V2(en/zh) | 46.5/32.3 | 45.2/39.6 | 51.9/43.1 | 45/46.2 | 47.8/46.1 | 61.5/63.7 |
CC-OCR | 66.6 | 62.7 | 73.0 | 64.7 | 68.7 | 79.8 |
Бенчмарки по видео:
Benchmarks | GPT4o | Gemini-1.5-Pro | InternVL2.5-78B | Qwen2VL-72B | Qwen2.5VL-72B |
|---|---|---|---|---|---|
VideoMME w/o sub. | 71.9 | 75.0 | 72.1 | 71.2 | 73.3 |
VideoMME w sub. | 77.2 | 81.3 | 74.0 | 77.8 | 79.1 |
MVBench | 64.6 | 60.5 | 76.4 | 73.6 | 70.4 |
MMBench-Video | 1.63 | 1.30 | 1.97 | 1.70 | 2.02 |
LVBench | 30.8 | 33.1 | - | 41.3 | 47.3 |
EgoSchema | 72.2 | 71.2 | - | 77.9 | 76.2 |
PerceptionTest_test | - | - | - | 68.0 | 73.2 |
MLVU_M-Avg_dev | 64.6 | - | 75.7 | 74.6 | |
TempCompass_overall | 73.8 | - | - | 74.8 |
Бенчмарки по "агентским" спосоностям:
Benchmarks | GPT4o | Gemini 2.0 | Claude | Aguvis-72B | Qwen2VL-72B | Qwen2.5VL-72B |
|---|---|---|---|---|---|---|
ScreenSpot | 18.1 | 84.0 | 83.0 | 87.1 | ||
ScreenSpot Pro | 17.1 | 1.6 | 43.6 | |||
AITZ_EM | 35.3 | 72.8 | 83.2 | |||
Android Control High_EM | 66.4 | 59.1 | 67.36 | |||
Android Control Low_EM | 84.4 | 59.2 | 93.7 | |||
AndroidWorld_SR | 34.5% (SoM) | 27.9% | 26.1% | 35% | ||
MobileMiniWob++_SR | 66% | 68% | ||||
OSWorld | 14.90 | 10.26 | 8.83 |
Заключение
Alibaba выпустили модель в 3 вариантах - 3, 7 и 72 миллиарда параметров. Более подробное описание можно посмотреть на HuggingFace, а сама модель лежит на GitHub.
Вот уж мощное начало года для китайских специалистов в ИИ.
---
P.S. 2025 год на дворе, неужели вы думали я не бахну ссылку на свой Телеграм канал в конце статьи? Я там регулярно пишу по ИИ/агентов, даю более глубокую аналитику по новостям, и рассказываю как сделать компанию, в которой все сотрудники — AI-агенты. Велком!












Написать комментарий