
Новый тест HLE выявил слабые места AI: 90% задач остаются нерешенными
Международная исследовательская группа разработала новый бенчмарк, который выявляет текущие ограничения LLM. Даже самые продвинутые модели не справляются с 90 процентами задач — на данный момент.
Тест под названием «Последний экзамен человечества» (HLE) включает 3000 вопросов по более чем 100 специализированным областям, 42 процента из которых посвящены математике. В его разработке приняли участие около 1000 экспертов из 500 учреждений в 50 странах.
Исследователи начали с 70 000 вопросов и представили их ведущим моделям AI. Из них 13 000 вопросов оказались слишком сложными для систем AI. Затем эти вопросы были доработаны и рассмотрены экспертами-людьми, которым платили от 500 до 5 000 долларов за высококачественный вклад. 3 000 вопросов попали в набор данных.
Результаты не лестные. Даже самые сложные модели AI с трудом справляются с этим бенчмарком. GPT-4o решает правильно только 3,3 процента задач, в то время как o1 от OpenAI достигает 9,1 процента, а Gemini — 6,2 процента. Сложность теста отчасти обусловлена его дизайном, поскольку в финальную версию были включены только вопросы, которые изначально ставили эти модели AI в тупик.
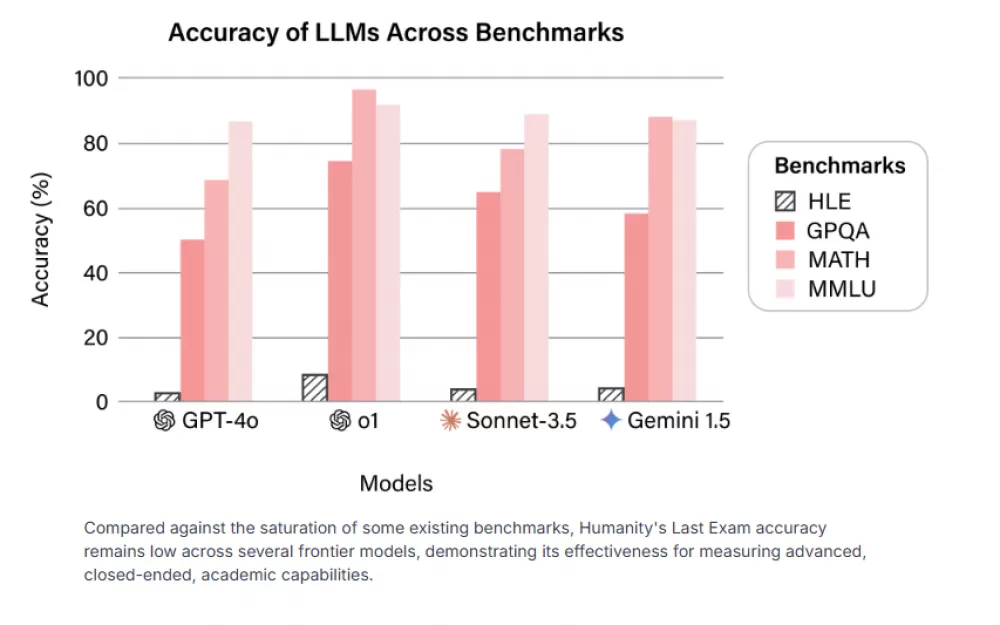
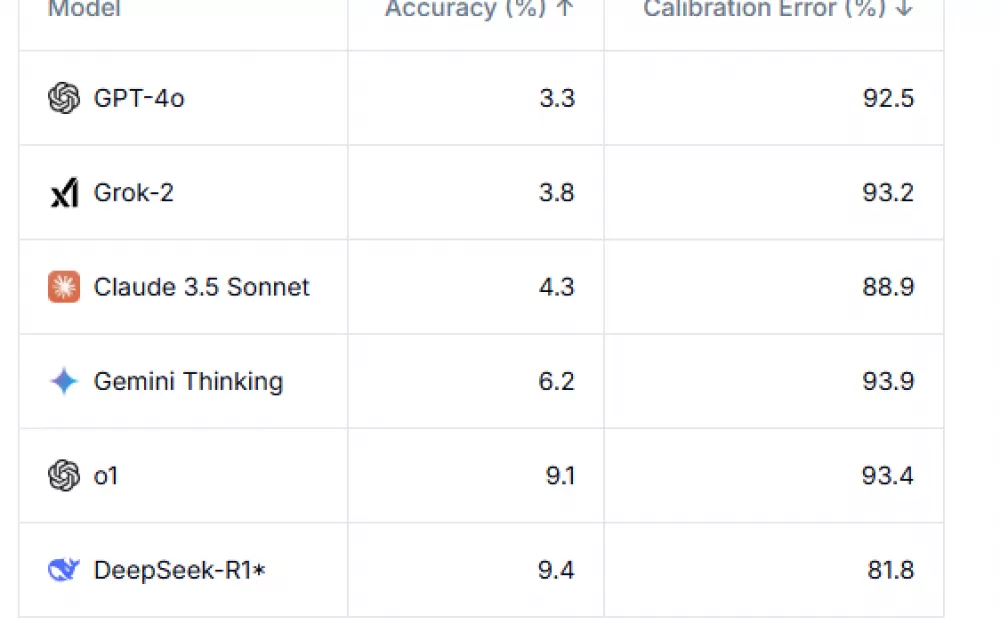
Ведущие модели ИИ имеют низкие показатели точности — ниже 10%, а ошибки калибровки постоянно превышают 80%. DeepSeek-R1 , протестированный только на тексте, достигает самой высокой точности — 9,4%. Gemini Thinking имеет самую высокую ошибку калибровки — 93,9%. Одной из наиболее тревожных находок является то, насколько плохо системы AI оценивают свои собственные возможности. Модели демонстрируют экстремальную самоуверенность, при этом ошибки калибровки превышают 80 процентов, что означает, что они обычно очень уверены в своих неправильных ответах. Этот разрыв между уверенностью и точностью делает работу с генеративными системами AI особенно сложной.
Тест охватывает широкий спектр академических дисциплин, включая классику, экологию, математику, информатику, химию и лингвистику. Проект появился в результате сотрудничества Центра безопасности ИИ и Scale AI. Дэн Хендрикс, который возглавляет Центр безопасности AI и консультирует стартап Илона Маска xAI, возглавил инициативу.
Эксперты выступают против концепции «окончательного теста»
Не все поддерживают этот академический подход к оценке AI. Суббарао Камбхампати, бывший президент Ассоциации по развитию искусственного интеллекта, утверждает, что сущность человечества не определяется статическим тестом , а скорее нашей способностью развиваться и решать ранее невообразимые вопросы. Эксперт по AI Нильс Рогге разделяет этот скептицизм, предполагая, что запоминание малоизвестных фактов не так ценно, как развитие практических способностей.
Бывший разработчик OpenAI Андрей Карпати отмечает , что, хотя академические тесты легко создавать и измерять, тестирование действительно важных возможностей AI, таких как решение сложных реальных задач, оказывается гораздо более сложной задачей.
Он рассматривает эти академические результаты бенчмарков как новую версию парадокса Моравеца : системы AI могут преуспеть в сложных задачах на основе правил, таких как математика , но часто испытывают трудности с простыми проблемами, которые люди решают без усилий. Карпати утверждает , что тестирование того, насколько хорошо система AI может функционировать в качестве стажера, было бы более полезным для измерения общего прогресса AI, чем ее способности отвечать на академические вопросы.

Разработчики бенчмарка прогнозируют, что к концу 2025 года системы AI будут правильно отвечать более чем на 50 процентов вопросов HLE. Однако сами они предостерегают от преждевременных интерпретаций.
Даже если модели AI достигнут этого рубежа, это не докажет существование искусственного интеллекта. Тест оценивает экспертные знания и научное понимание, но только с помощью структурированных академических задач — он не оценивает открытые исследовательские вопросы или творческие способности решения проблем.
Как отметил Кевин Чжоу из Калифорнийского университета в Беркли в интервью The New York Times : «Существует огромная пропасть между тем, что значит сдать экзамен, и тем, что значит быть практикующим физиком и исследователем. Даже AI, который может ответить на эти вопросы, может оказаться не готов помочь в исследовании, которое по своей сути менее структурировано».
Реальная ценность теста может заключаться в том, что он поможет ученым и политикам лучше понять возможности AI, предоставив конкретные данные для обсуждения вопросов развития, рисков и регулирования.
Источник












Написать комментарий