Новая AI-модель от ByteDance оживляет статичные изображения с помощью звука
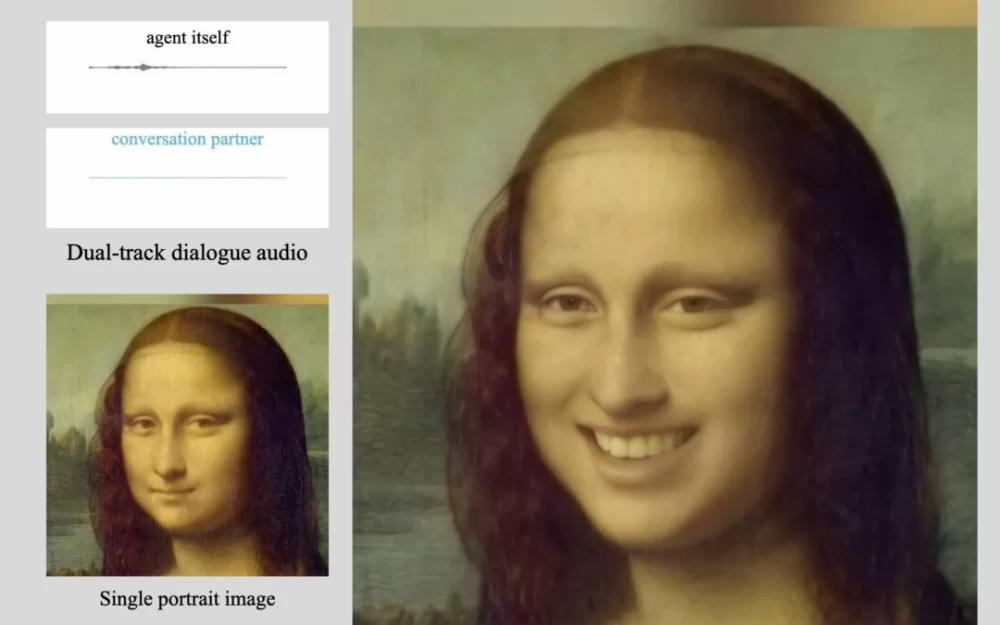
Материнская компания TikTok, ByteDance, разработала систему AI под названием INFP, которая способна заставлять статичные портретные фотографии говорить и реагировать на аудиовход.
Что отличает INFP (Interactive, Natural, Flash and Person-generic) от других, так это его способность создавать реалистичные видео разговоров между двумя людьми без необходимости вручного назначения ролей говорящего и слушающего. Система автоматически определяет эти роли по ходу разговора.
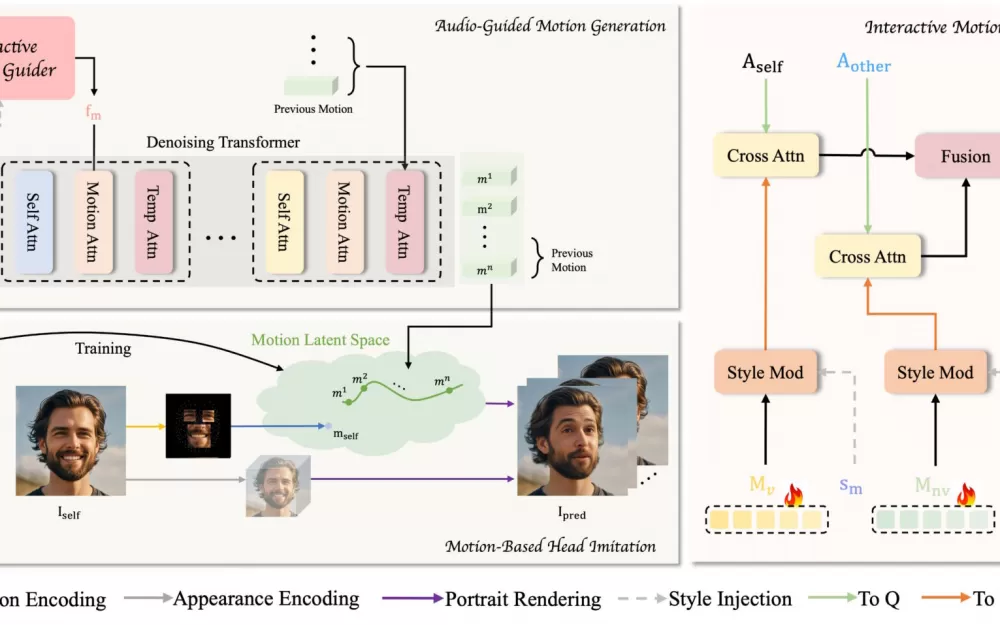
Система работает в два основных этапа. На первом этапе, который ByteDance называет "Motion-Based Head Imitation" (Имитация движений головы на основе движения), AI учится учитывать все мелкие детали того, как люди общаются — такие как мимика и движение головы во время разговоров. Он берет эти движения из видео и превращает их в данные, которые можно использовать позже. Эти данные о движении затем могут анимировать статическое фото, соответствуя движениям исходного человека.
На втором этапе, "audio-guided motion generation" (генерация движения с управлением по звуку), система определяет, как сопоставлять звуки с естественными движениями. Команда разработала то, что они называют "motion guider" (руководитель движения), который создает паттерны как для говорения, так и для слушания, анализируя аудио с обеих сторон разговора. Затем специальный компонент AI, называемый диффузионным трансформером, постепенно уточняет эти паттерны до плавных, реалистичных движений, соответствующих аудио.
Чтобы правильно обучить свою систему, команде пришлось создать нечто новое: коллекцию реальных разговоров, которую они назвали DyConv. Они собрали более 200 часов разговоров людей из видео в интернете.
Хотя существуют и другие базы данных разговоров, такие как ViCo и RealTalk, команда утверждает, что DyConv предлагает нечто особенное — она охватывает более широкий спектр человеческих эмоций и выражений, а качество видео заметно лучше.


ByteDance заявляет, что их система превосходит существующие инструменты по нескольким ключевым параметрам. INFP особенно хорошо сопоставляет движения губ с речью, сохраняет уникальные черты лица человека и создает широкий спектр естественных движений. Команда также обнаружила, что система хорошо работает для создания видео, где человек просто слушает разговор.
В настоящее время INFP работает только с аудио, но команда видит множество способов расширения его возможностей. Они исследуют, как сделать систему работающей с изображениями и текстом, что откроет множество новых возможностей. Их следующая цель — создание реалистичных анимации целых тел людей, а не только их голов и мимики.
Исследователи понимают, что этот вид технологий может быть злоупотреблен для создания фальшивых видео и распространения ложной информации. Поэтому они планируют оставить основную технологию доступной только для исследовательских учреждений — подобно тому, как Microsoft поступила прошлым летом со своей усовершенствованной системой клонирования голоса.
Эта работа — лишь одна из частей более широкой AI-стратегии ByteDance, которую они объявили ранее в этом году. С популярными приложениями, такими как TikTok и CapCut, в своем портфеле, компания обладает огромной платформой для использования этих инноваций в области AI.
Источник












Написать комментарий