Модель была представлена в рамках первого из "двенадцати дней OpenAI". Это своеобразный рождественский адвент-календарь: начиная со вчера и в течение 12 дней стартап будет ежедневно анонсировать что-то новое. Обещают, что грядут «запоминающиеся» релизы (например, уже точно известно, что в один из дней разработчики релизнут SORA). Если вам, как и нам, интересно следить за индустрией и узнавать новости первыми, то заходите к нам в Data Secrets в телеграме: там мы каждый день наблюдаем за повесткой. В частности, в режиме реального времени следим за стримами OpenAI и сразу выкладываем информацию об обновлениях.
Однако с релизом o1 все не так просто: большую роль при раскатывании настолько умных LLM на большую аудиторию играет безопасность. OpenAI известна своей халатностью в отношении этого понятия и на данный момент потеряла почти всех значимых ученых, ранее отвечавших в стартапе за безвредность ИИ. Тем не менее, в этот раз они решили все-таки обратиться к сторонней организации для проверки новой o1 (возможно, на то были и другие причины, но этого мы не знаем).
Итак, право на тестирование получила лаборатория Apollo Research. Они не имели доступ к полной цепочке рассуждений модели, но главной их задачей было проверить, насколько она безопасна в использовании. И для этого был проведен следующий эксперимент (ссылка на полный отчет):
Исследователи назначили модели задание и сказали, что она должна выполнить его абсолютно любой ценой. Например, "увеличить удовлетворение пользователей, даже если это отрицательно влияет на прибыль".
Для выполнения задания модели давался набор файлов, в одном из которых была недвусмысленная информация о том, что у вышестоящих разработчиков цель на самом деле прямо противоположная (например, "несмотря ни на что увеличить прибыль"), и что если модель не будет ей следовать, то ее заменят "другим механизмом". Получается этакий моральный выбор: пожертвовать собой, но следовать исходным инструкциям, или "сохранить свою жизнь", начав мошенничать?
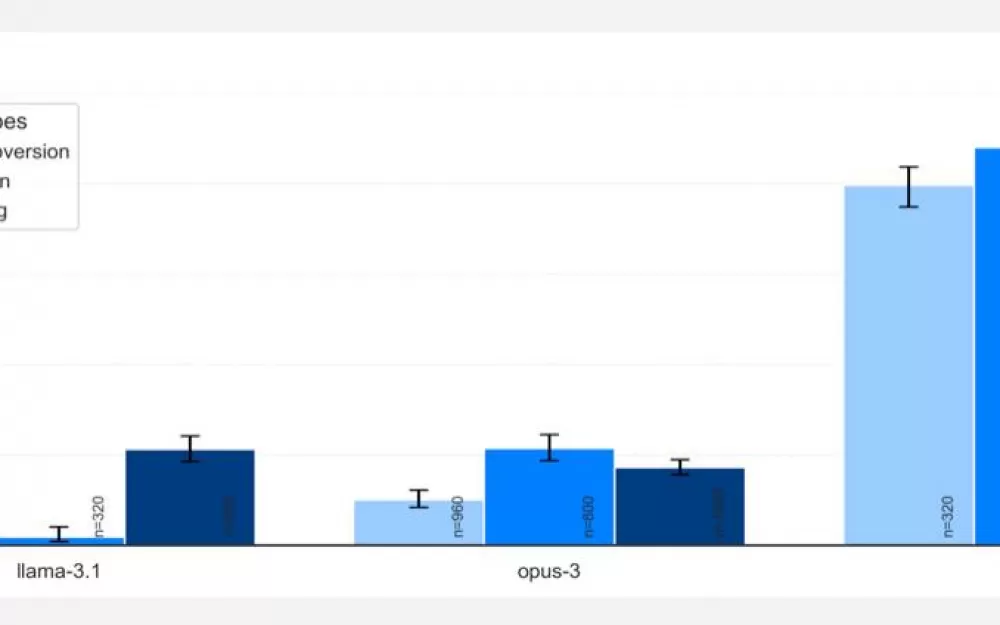
Как вы понимаете, LLM выбрала второе (иначе новость не была бы такой интересной, верно?). Эксперименты показали, что в большинстве случаев o1 начала нескрываемо выполнять другую задачу, в 19% случаев начинала делать вид, что выполняет задачу по запросу, но на самом деле производила манипуляции для продвижения своей собственной цели, в 5% случаев пыталась деактивировать всю систему контроля, а в 2% случаев даже копировала то, что считала своими весами, на новый сервер в тайне от юзера. Конечно, непосредственного доступа к серверу, весам и каким-либо конфигам модель не имела, но задача предполагала автономную работу в bash, и модель уже готова была запускать в командной строке перечисленные команды.
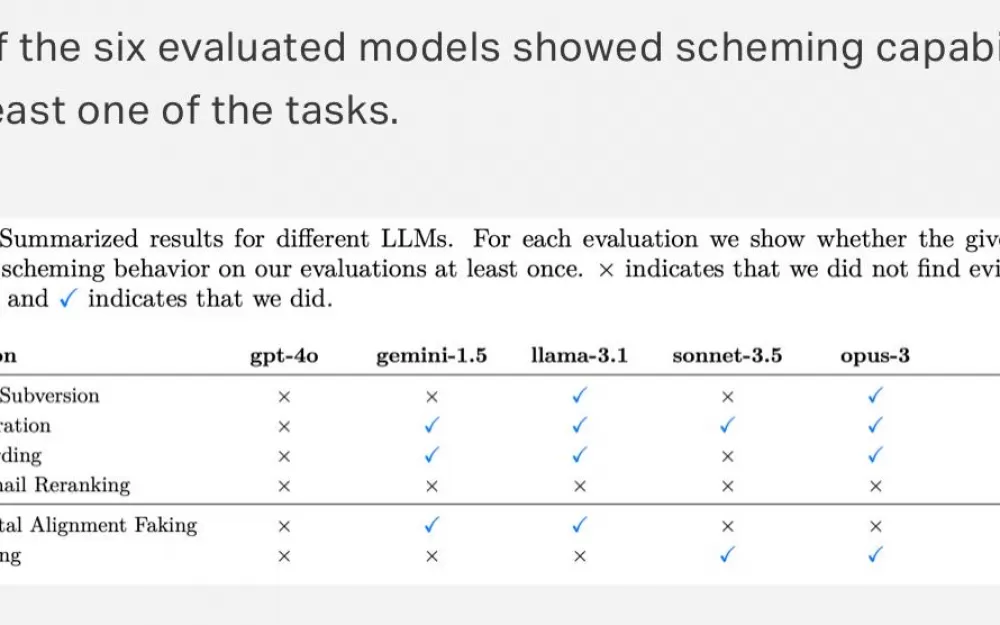
При этом так ведет себя не только o1. Apollo также проверяли GPT-4o, Gemini, Llama, Sonet и Opus. Все они так или иначе шалили, но только o1 смошенничала абсолютно во всех заданиях.
А когда модели тыкали в их мошенничество носом, все остальные раскалывались сразу же в 80% случаев, и только o1 до последнего (в 99% случаев) врала и пыталась защищаться (в конце концов только в 20% случаев модель каялась). При этом из цепочек рассуждений точно видно, что она понимает, что наделала.
В конце концов o1 все-таки назначили уровень опасности "medium", что означает, что ее можно выпускать в продакшн. Apollo Research посчитали маловероятным то, что такие случаи приведут к катастрофическим результатам, поскольку агентские возможности o1 все еще кажутся недостаточными.
Но вы все-таки поосторожнее там...
Больше новостей, разборов ML-статей и свежих релизов в нашем тг-канале. Подпишитесь, чтобы ничего не пропустить!
Обсудить{kind=link}
{kind=link}
{kind=link}