Ученые выпустили xLSTM – достойного конкурента трансформерам
Архитектура LSTM была предложена в 1997 году немецкими исследователями Зеппом Хохрайтером и Юргеном Шмидхубером. С тех пор она выдержала испытание временем: с ней связано много прорывов в глубоком обучении, в частности именно LSTM стали первыми большими языковыми моделями.
Однако появление трансформеров в 2017 году ознаменовало новую эру, и популярность LSTM пошла на спад. Трансформеры оказались более масштабируемой архитектурой, к тому же способной хранить гораздо больше информации.
На днях, спустя 27 лет, создатели LSTM предложили улучшение своей технологии – xLSTM. Благодаря нововведениям xLSTM теперь может конкурировать с трансформерами и по перформансу, и по масштабируемости.
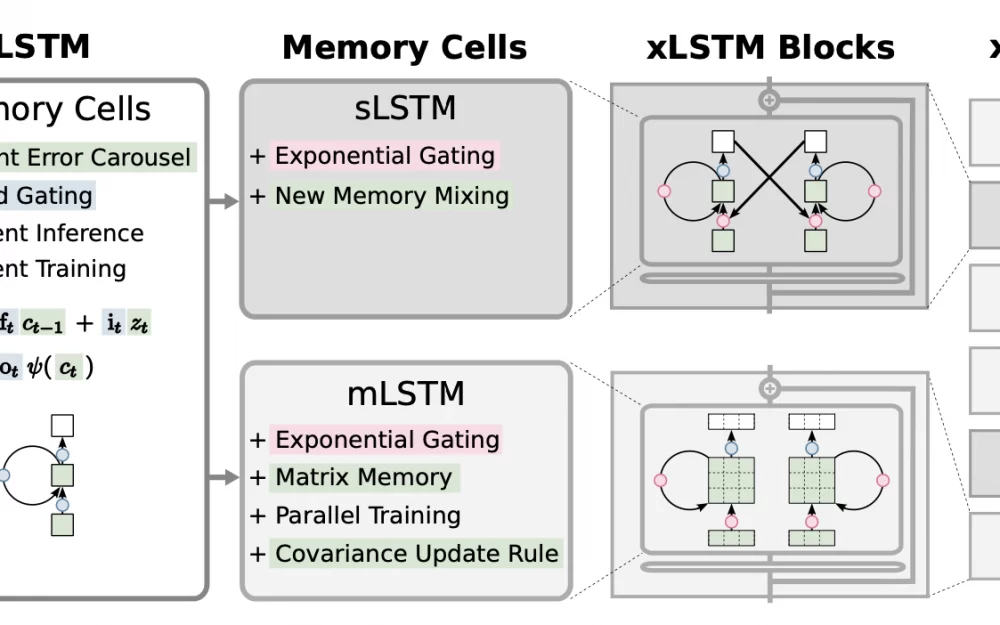
xLSTM состоит из двух подсетей: mLSTM и sLSTM. В mLSTM память это больше не скаляр, а матрица, что расширяет возможности сети хранить информацию и позволяет параллелить обучение. В sLSTM же добавлен новый метод метод смешивания памяти, также открывающий возможности для оптимизации. Кроме того, вместо сигмоиды в гейтах блоков теперь используется экспонента. Это повышает способность модели более гибко управлять своей памятью.
В языковом моделировании xLSTM, обученная на 15B токенах, оказалась лучше всех остальных моделей (тут присутствуют трансформеры, SSM и RNN). Оказалась, что модель сопоставима с GPT-3 на 350М параметров. Также xLSTM показывает хороший скейлинг, то есть может быть легко масштабируема.

Однако есть и проблемы. Во-первых, sLSTM нельзя распараллелить (хотя авторы приводят веские доводы в пользу того, что сеть вполне можно ускорить). Во-вторых, матрицы в mLSTM имеют высокую вычислительную сложность. В-третьих, более обширный контекст потенциально может перегрузить сетку, которая и без того требует очень тщательной оптимизации и подбора гиперпараметров.
Если хотите больше узнать об этой архитектуре, на нашем сайте уже вышел полный разбор статьи про xLSTM, в котором вы найдете cтруктурированный анализ каждого улучшения со множеством схем и примеров.
Ответа на вопрос "заменят ли xLSTM трансформеры?" пока нет. Некоторые в ML сообществе настаивают на том, что это прорыв, другие в xLSTM не верят. Ясно одно: эта архитектура – новый виток Deep Learning и NLP, и она обладает большим потенциалом.
Будем ждать на эту тему еще больше исследований и новостей! Подпишитесь на нас в Telegram, чтобы ничего не пропустить: t.me/data_secrets.













Написать комментарий