
Nvidia выпустила NVLM 1.0 – собственную мультимодальную LLM, которая на некоторых тестах опережает GPT-4o
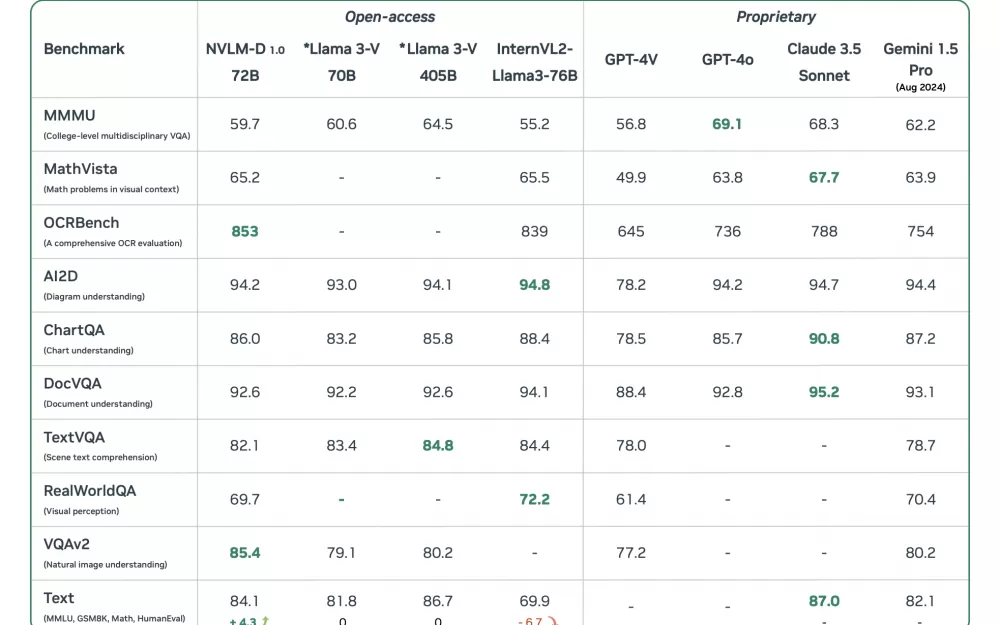
NVLM 1.0 – это семейство открытых мультимодальных LLM, состоящее из моделей NVLM-D , NVLM-X и NVLM-H на 34B и 72B. Модели особенно хорошо показывают себя на визуальных задачах. Например, на бенчмарке OCRBench, который проверяет способность модели считывать текст с картинки, NVLM-D обогнала даже GPT-4o – последнюю мультимодальную модель от OpenAI. А еще модель понимает мемы, разбирает человеческий почерк и хорошо отвечает на вопросы, чувствительные к точному местоположению чего-либо на картинке.
На вопросах по математике модель тоже выделяется: обгоняет LLM от Google и всего на 3 пункта отстает от ведущей модели Claude 3.5 известного стартапа Anthropic. Внизу в таблице представлены все опубликованные тесты, и обратите внимание, насколько высоких относительно других открытых моделей (даже бОльшего размера) результатов удалось добиться Nvidia.
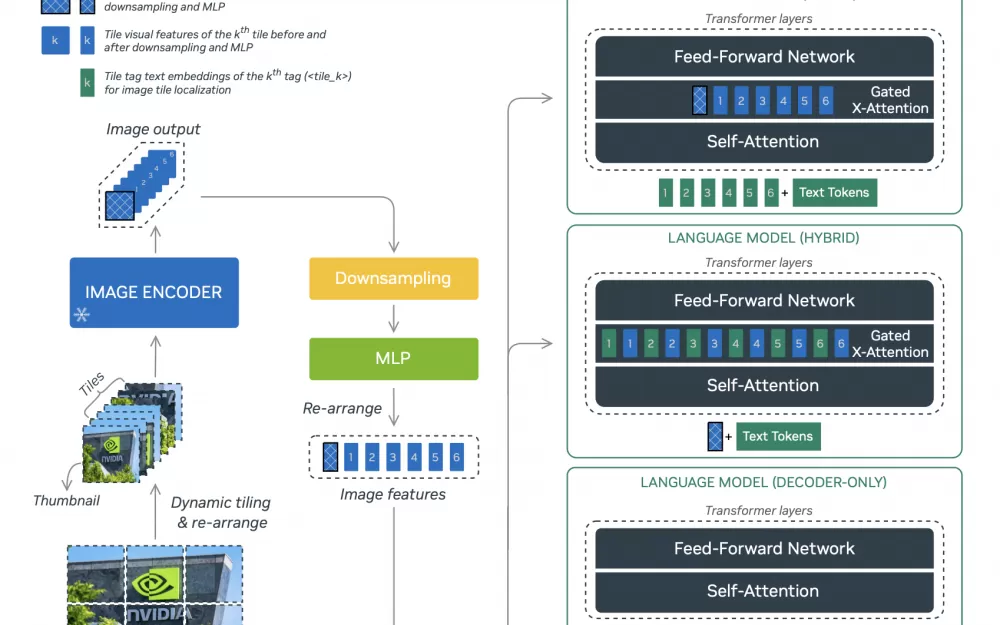
Три разные модели семейства имеют схожую архитектуру, но обладают разными особенностями и, в частности, по-разному обрабатывают изображения. NVLM-D использует для картинок предобученный энкодер, который соединен с обычным двухслойным перцептроном. NVLM-Х же для обработки токенов изображения использует механизм cross-attention. У каждого из подходов есть недостатки и преимущества. Например, NVLM-D более экономный относительно количества параметров, но ест больше GPU и хуже, чем NVLM-X, обрабатывает картинки с высоким разрешением. Так что модель NVLM-H стала чем-то средним между эффективной и быстрой NVLM-D и точной NVLM-Х. Подробнее обо всех упомянутых алгоритмах, языковых моделях и новых релизах можно прочитать в нашем тг-канале Data Secrets (мы выкладываем только самое полезное, свежее и интересное!).
Больше технических деталей можно найти в статье. Веса самих моделей скоро можно будет найти на Hugging Face, а в этом репозитории лежит код.













Написать комментарий