
Framework для автоматизации тестирования на Java
Привет, Хабр! В нашем сегодняшнем материале тестировщики Максим Жигарев и Артем Сенько из Блока ИТ‑развития инвестиционного бизнеса РСХБ‑Интех расскажут, как они автоматизировали тестирование в ИвестБлоке с использованием Java. Материал основан на докладе, с которым Артем и Максим выступили в рамках внутреннего митапа для сотрудников РСХБ.
Для начала расскажем, почему мы вообще решили делать что‑то свое, а не воспользовались готовым решением. До прихода в РСХБ мы успели поработать в нескольких ведущих банках и маркетплейсах. Везде использовались разные подходы к автоматизации и разные фреймворки для автотестов. Где‑то команда делала что‑то свое и не было общего подхода. А раз у одних свое, у других свое, то люди в разных командах не стремились коммуницировать друг с другом. Бывали случаи, когда одна команда уже научилась работать с инструментом или какой‑то технологией, набила шишки, наступила на все грабли, а другая только начинала путь, не зная об опыте коллег. Также отдельно хотелось бы подчеркнуть, что фреймворк, который вы выбрали, не всегда может содержать решение из коробки. Например, если на текущий момент он покрывает все ваши потребности, то по прошествии времени в вашу систему может добавиться функционал, и этот фреймворк уже не будет включать решения для работы с ним.
Ну и не забываем про известные проблемы с багами. Баги могут содержать как стандартные библиотеки, лежащие в основе фреймворков, так и сами фреймворки. И, если мы на что‑то натыкаемся, то весьма дорого обходится поиск решения этих проблем. Еще можно добавить проблемы с версионностью. Если мы захотим обновить версию фреймворка, то, возможно, получим новый функционал или фикс каких‑либо известных багов. Но это не гарантирует нам, что не появится новых багов или старый функционал у нас будет работать так же, как и в прошлой версии.
Учитывая все эти моменты, мы приняли решение, что хотим взять за основу стандартные библиотеки, добавив к ним удобный интерфейс и применив наши требования. Перейдем к тому, что у нас получилось.
Начнем с базы данных. Для работы с БД мы выбрали Hibernate. Он широко известен как в кругу автоматизаторов, так и в кругу просто разработчиков. Hibernate — это фреймворк для Java, предназначен для работы с базой данных. Объекты в нем описываются на языке программирования с применением принципов объектно‑ориентированного программирования. Запросы в базу можно писать как в стандартном виде SQL, так и с помощью HQL. HQL — это Hibernate Query Language — объектно‑ориентированный язык запросов, который очень похож на SQL, но, в отличие от него Hibernate работает с объектами и полями, в то время как SQL работает с таблицами и столбцами в базе.
Ниже можно увидеть пример работы с базой. Для начала нам нужно подключить нашу библиотеку в тестовый проект, а при реализации самого класса с запросами необходимо наследоваться от класса библиотеки. Мы задаем стандартные параметры, такие как host, port, имя пользователя, пароль и указываем драйвер подключения. В примере приведен Postgres, но также можно указать MySQL или любой другой. В конце мы инициализируем сессию.

Далее у нас пример того, как выглядит сам запрос в формате HQL. Используемый в запросе join — одна из особенностей HQL. Нам необходимо указать только необходимость join, а сам join описываем один раз в классе.
Мы указываем аннотацию с типом связи, в данном случае это ManyToOne, то есть «многие к одному», но можно указать любую из известных типов связи, например, «один к одному», «один ко многим» и так далее. В аннотации JoinColumn мы указываем наименование столбца текущей таблицы и наименование столбца таблицы, которую join‑им. Соответственно, если по каким‑либо причинам у нас этот join меняется, нам не нужно править все запросы, которые мы описывали, мы правим только само описание в классе.
Здесь же приведен пример того, как логируется наш запрос: join уже в привычном нам виде. Сам залогированный запрос мы можем скопировать и выполнить в любом клиенте для работы с базой данных.

Раз уж мы затронули вопрос логирования, сразу покажем одну из наших доработок в этой части. Ниже пример того, как запрос логирует сам Hibernate. Как мы видим, в самом select указано каждое поле таблицы, и при этом оно переименовано не очень понятно, что уже усложняет чтение самого запроса, если полей в таблице очень много. Переименование полей не очень критично, если их немного, и пока худо‑бедно мы можем выполнить этот запрос. Второе, на что здесь можно обратить внимание, это знаки вопроса в месте, где у нас подставляются параметры. Это доставляет сложности при самостоятельном выполнении данного запроса. То есть нам нужно либо убрать это условие, либо самостоятельно вписать туда нужные значения. В том виде, в котором логирует Hibernate, мы не можем просто взять запрос и выполнить его.
Теперь переходим к нашей доработке. Рядом представлен запрос без этого множества непонятных полей и уже с подставленными значениями. Значит, мы можем просто скопировать и выполнить в любом редакторе базы данных.

Следующая наша доработка касается подстановки значения в запрос. Изначально у Hibernate был метод setParameter() для передачи одного значения. Данный метод осуществляет валидацию переданного значения: если это строка, мы должны передать строку; если дата, то дату. Если мы передадим не тот тип данных, получим ошибку. У этого метода обнаружился дефект. При значении параметра равного null, в select Hibernate подставляет «= null». Но, как все знают, SQL‑запрос должен выполняться с «is null», а если указать «= null», то, по сути, мы ничего не выберем. Соответственно, мы этот момент у себя поправили, и для select у нас будет подставляться корректное условие, для апдейта останется «= null».
Также мы реализовали дополнительный метод changeParameter(). И, если в setParameter() мы можем передавать только конкретные значения, то в changeParameter() мы можем передавать целые условия, подзапросы и так далее. Например, параметр startDateTime, в него мы передаем условия либо больше текущего времени, либо подзапрос.

В дополнение к changeParameter() сделали еще один метод — changeParameterWithEmptyValue(). Он в работает так же, как обычный changeParameter(), но есть одно важное отличие — если переданное значение равно null, мы удаляем строку целиком, в которой этот параметр находится. Например, для «far.frequency» либо подставится значение, либо эта строка будет удалена, если мы передадим значение null. Это сделано для того, чтобы не описывать множество одинаковых запросов в коде, а потом искать нужный тебе в зависимости от ситуации.

Также мы реализовали возможность для повторного выполнения запроса. Рассмотрим пример: нам нужно провалидировать данные в базе системы, которую мы не контролируем. То есть эти данные попадают туда, проходя одну или несколько интеграций, и, ввиду различных факторов, время на осуществление этих интеграций может варьироваться. Чтобы нам не ждать каждый раз какое‑то константное время, мы реализовали механизм retry. Мы можем задать максимальное количество попыток, время между осуществлением этих попыток или максимальное время ожидания получения данных.

Следующая наша доработка — это доработка по возможности осуществления пустой выборки. Что это значит? Например, мы делаем запрос и хотим получить единичный результат, но, если мы ничего не находим в базе, то Hibernate выдаст нам ошибку. Бывают такие ситуации, когда мы, наоборот, хотим проверить, что в базе ничего не появилось. Для этого мы реализовали метод enableEmptyResult(). Вызвав его, мы не получим ошибку, а просто вернем null. Противоположная ситуация с получением списка. Здесь Hibernate не выдаст ошибку, а, наоборот, вернет пустой список. Но, чаще всего, если мы в запросе ничего не выбрали, то зачем нам двигаться дальше. Для этого мы реализовали метод getNotEmptyResultList(), вызвав его и получив пустую выборку, наш тест упадет с ошибкой на этом этапе.

Еще одна из реализованных доработок — это возможность работы с динамической схемой. Ниже показано стандартное описание класса. В аннотации Table мы указываем название таблицы и название схемы. Но бывает так, что на различных стендах схемы одной базы данных у нас могут различаться. В таком случае мы можем передать в качестве названия схемы константу и в параметрах подключения к базе данных указать её наименование. При формировании запросов нам уже не нужно будет переживать, в какой схеме мы делаем запрос. Также связанная с этим доработка — это указание схемы по умолчанию при осуществлении самого подключения к базе данных. Бывают ситуации, когда при добавлении каких‑либо записей в таблицу будет срабатывать какой‑то триггер и запускать процедуру, а эта процедура будет выполняться в той схеме, к которой мы подключились. Соответственно, в этой ситуации нам недостаточно указать схему в самом запросе, нужно указывать схему при осуществлении подключения к самой базе. Тогда нам нужно просто в параметрах подключения указать схему по умолчанию. И соответственно запросы будут выполняться уже в конкретной схеме.

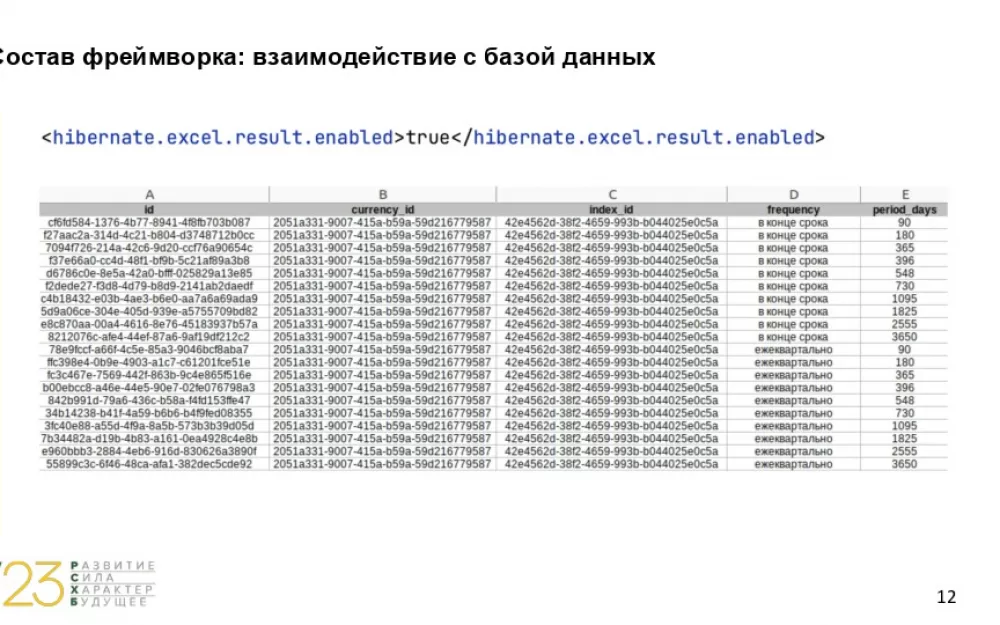
Последняя из доработок по базе, про которую мы хотим рассказать — это возможность генерации excel‑документа по результатам выборки. Ниже представлен пример excel. Названия колонок соответствуют названиям столбцов в базе данных. Этот excel будет прикреплен к allure‑отчету, который у нас формируется по результатам прогона тестов. Включить формирование excel можно просто выставив системную переменную в true.
Следующее, о чем хотели бы рассказать, это работа с WebSocket. Он нужен для того, чтобы создавать соединение между сервером и клиентом и обмениваться сообщениями в реальном времени. Для подключения используется стандартный наш подход: мы наследуемся от класса из нашей библиотеки, и остается только указать параметры для подключения к WebSocket. В самом тесте мы можем подписаться на нужный нам топик, и при отписке мы получим список событий, с которыми можно работать.
В качестве названия топиков мы передаем не просто строковое значение, а используем Enum. Она нужна для того, чтобы все наши названия хранились в одном месте, и не приходилось в каждом тесте при необходимости менять наименование топиков. Ну и также плюс, что в одном месте видим все топики, с которыми мы работаем.


Еще одна возможность фреймворка — это работа с брокером сообщений IBM MQ. Ниже пример того, как у нас реализована работа с Browser. Как и в других местах, просто наследуемся от нашей библиотеки и задаем параметры подключения. В самом тесте вызываем метод чтения. Также у нас реализована работа с Consumer. Отдельно его реализацию показывать не будем, она такая же, как и у Browser. Но есть отличие в их работе — Browser просто просматривает сообщение и вернет вам список, а Consumer выступает потребителем, поэтому после прочтения сообщение пропадет из очереди. Работа с Producer аналогична. Также наследуемся от необходимого класса из библиотеки, в самом тесте просто вызываем метод отправки. Как и в WebSocket — аналогичная Enum для очередей, чтобы все хранилось в одном месте.


Далее переходим к работе с Rest API. За основу мы взяли всем известную библиотеку Rest Assured, но доработали ее под свои нужды. Вначале наследуемся от класса и на первом этапе вызываем метод, который возвращает нам билдер из этой библиотеки. Он формирует корневую структуру запроса. Там мы меняем настройки логирования запросов и ответов, перерабатываем формат того, как это все собирается для allure‑отчета. Далее пример метода, который вызывается из самого теста для отправки запроса.

Ниже пример, как у нас логируется запрос в консоли. Здесь можно увидеть тип запроса, адрес, куда он отправляется, параметры, заголовки, с которыми будет отправлен и так далее.

А здесь пример уже того, как логируется ответ в исходном виде Rest Assured. В принципе, здесь можно понять, что началось логирование ответа только по косвенным признакам, например, по статус‑коду. Также вместе слеплены заголовки, куки и тело ответа просто начинается через пустую строку.
Правее пример того, как мы доработали логирование ответа. Мы добавили явные разделения для логических блоков ответа. Теперь видно, где начинается сам ответ, заголовки, тело ответа и так далее. Также если в ответе у нас возвращается файл, то стандартно Rest Assured выведет его в консоль в формате base64. Этот момент доработали и выводим только название и тип файла, потому что набор символов особо ничего полезного не принесет, и, к тому же, от этого засоряются логи.

В части Rest Assured мы доработали не только логирование, но и добавили очевидные проверки, например, на статус‑коды, пустые тела ответов и так далее. В каждом тестовом проекте вам не нужно их описывать отдельно, они уже все есть, они будут логироваться в отчет, вам ни о чем не надо думать.
В стандартном классе ответа Rest Assured есть метод then(), который позволяет получить атрибуты ответа, как тело, заголовки и так далее. Чтобы не прокидывать по всем тестовым методам объект ответа, мы реализовали одноименный метод then(), который хранит в себе последний полученный ответ, и его можно вызывать уже непосредственно из методов с проверками, не прокидывая при этом туда сам ответ через множество методов.

Далее переходим к работе с Kafka. Здесь мы взяли за основу стандартную библиотеку на Java для работы с Kafka и сделали обертку для нее. Спрятали внутрь все технические моменты, например, то, как осуществляется подключение, работа с сериализацией, работа с сертификатами и так далее. Ниже пример того, как построена работа с Producer. Наш стандартный подход: мы наследуемся от класса из библиотеки и задаем только параметры для подключения. Далее в самом тесте нам нужно вызвать только метод для отправки сообщения, где мы указываем topic, куда отправляем сообщение, ну и само сообщение соответственно. Также есть возможность указать ключ для сообщения, если он не будет указан, тогда сообщение отправится с ключом null.

Далее работа с Consumer. Аналогичная реализация: также наследуемся и задаем параметры для подключения. Здесь хотим обратить внимание на такие параметры, как prefix и postfix. Эта наша доработка. Она возникла из‑за того, что на разных стендах могут быть разные префиксы у названий топиков. То есть, если kafka развернута локально, то название топика будет в исходном виде. Если, например, это на dev стенде, то добавится prefix. Иногда наоборот может добавляться postfix. И мы сделали так, что в тестах мы работаем со стандартными названиями топиков, а префиксы и постфиксы задаем на уровне конфигов, и уже не нужно думать в тестах на каком стенде, с какими префиксами у тебя это выполняется.

Для consumer мы реализовали различные методы для вычитки сообщений. Например, метод readFirstByKey() вернет объект, который будет содержать само сообщение, ключ и время записи в топик. Сообщение вернется в формате строки. При вызове метода мы указываем только топик и ключ поиска. Если ключ не указываем, то выберется последнее сообщение. Можно вычитать как одно сообщение, так и список. В таком случае название метода будет начинаться не с readFirst, а с readAll. Также реализованы методы, которые вернут не строку, а сразу объект или список объектов, с которыми можно дальше работать в тестах. Для этого реализованы методы, которые работают как с JSON, так и с XML.
Все эти методы нацелены на получение какого‑либо результата. Соответственно, если мы ничего не сможем найти по заданному ключу, то тест будет провален, и дальше мы не идем. Но бывают обратные ситуации, когда нам, наоборот, нужно проверить, что в топик ничего не отправилось. Для таких случаев мы реализовали аналогичные по названию методы, но с припиской withEmptyResult. В таком случае, если мы ничего не найдем, то вернется null, а если найдем, то вернем найденную запись.
Ну и последний метод, про который хотим рассказать, это метод, который задает время вычитки сообщения от текущего времени. Например, в топик могут попадать одинаковые сообщения, и это будет нормальная валидная ситуация. Допустим тест идет 5 секунд и соответственно нас интересуют сообщения в топике, которые появились в эти 5 секунд. Для этого мы задаем интервал и исключаем ту ситуацию, когда у нас случайно выберется не то сообщение, которое было в топике до прохождения нашего теста.
По результатам каждого прогона тестов у нас автоматически формируется allure‑отчет. Он может формироваться как локально, так и при прогоне через Gitlab CI. Ниже представлен пример отчета. Виден список сценариев, которые покрыты тестами, и в правой стороне раскрыт сценарий — один из вариантов его описания. Внутри описываются все Rest‑запросы, которые мы отправляем, запросы к базе данных, то, что мы отправляем в очередь, и так далее. Таким образом, получается, что даже человек, который не знаком с тестированием, может зайти, посмотреть отчет, понять, какие сценарии были проверены, и дать свои комментарии либо просто ознакомиться с тем, какой функционал был проверен и как он был проверен.

Далее расскажем подробнее про то, как в отчете отображаются действия по функциональности, о которой мы рассказывали выше. Ниже, например, представлен вид отчета по работе с WebSocket и с Kafka. То есть мы осуществляем подписку на WebSocket, далее отправляем сообщение в топик Kafka. В конце осуществляем отписку от вебсокета и уже проверяем сообщение, которое мы получили.

Далее пример того, как в allure отображена работа с rest‑запросами: какой запрос мы отправляем, на какой адрес, приложен curl, заголовки и так далее. И аналогично пример ответа: какой статус‑код, заголовки, тело ответа, если есть файл, то прикладывается этот файл, который мы можем скачать и посмотреть.

Ниже пример того, как отображается запрос в базу в allure отчете. Например, Select, мы можем отсюда скопировать его и выполнить в базе данных. До этого рассказывали про Excel, который формируется по результатам выборки — он будет приложен рядом с запросом, и мы можем посмотреть, что у нас выбралось.

Так же мы настроили интеграцию автотестов с системой Test IT. Мы переработали библиотеку, которая отвечает за эту интеграцию, и в результате информация в Test IT стала более структурированной и понятной. Все автоматизированные сценарии сразу попадают в Test IT, и их можно слинковать с ручными сценариями. Слева отображается дерево с функциональными блоками системы, а справа — непосредственно разбиение на сценарии, которые покрывают тот или иной функциональный блок.
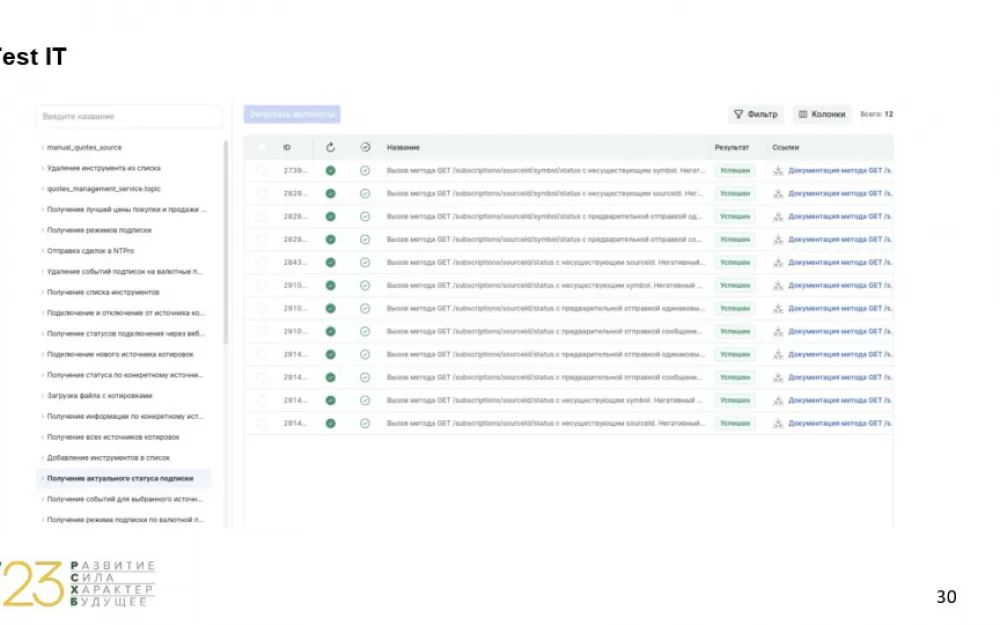
Далее представлена внутренность сценария в Test IT. Аналогично allure, здесь отображена информация о том, какие запросы мы отправляем post, get, curl запроса, все сообщения, которые были отправлены в kafka, запросы в базу данных, проверки и так далее.

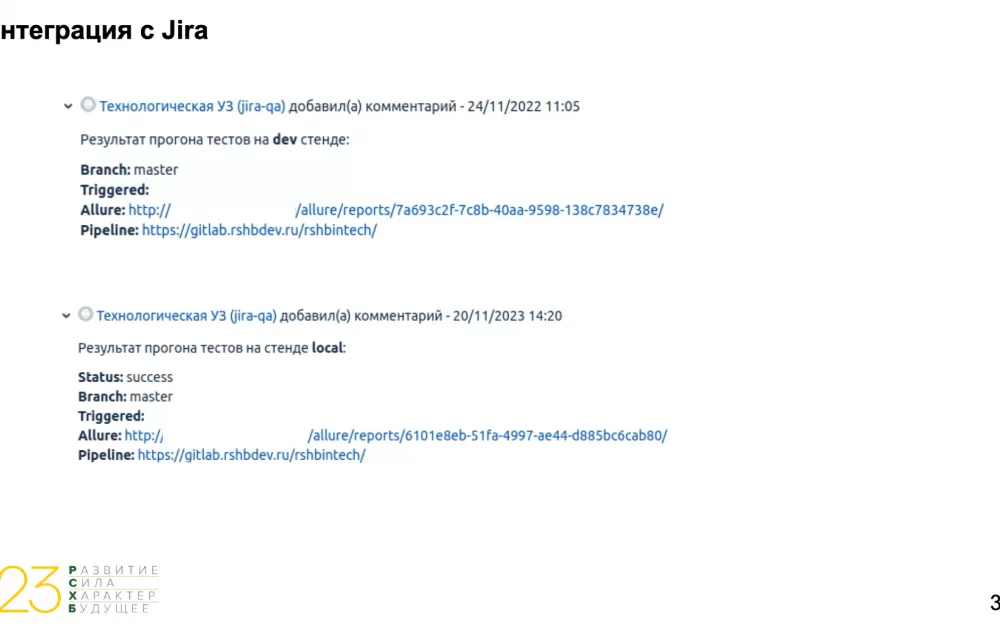
Еще хотели бы рассказать про интеграцию с Jira. Для всех прогонов в Gitlab CI у нас реализована возможность автоматически прикреплять комментарии к задачам в Jira. Комментарии содержат информацию о том, кто запустил прогон, на каком стенде, ссылку на allure‑отчет, из какой ветки запускались тесты и ссылку на сам пайплайн.
На данный момент наш фреймворк включает работу с базой данных, работу с WebSocket, Kafka, RestApi, Allure‑отчеты, интеграцию с Test IT, работу с IBM MQ, Selenide. Также у нас есть Common Library — это наша общая библиотека, в которой мы переработали ассерты, унифицировали работу с параметрами тестов, реализовали механизм многопоточной работы в рамках одного тестового сценария.
Все, о чем мы вам рассказали, упрощает, во‑первых, процесс начала работы с данным фреймворком. На первых порах вам не нужно думать, что зашито под капотом методов, просто берете и используете их. Плюс вы не думаете, как подключиться к базе или отправить сообщение в kafka. Интерфейс везде одинаковый, задаются только базовые параметры.
Во‑вторых, используются обертки над стандартными и популярными библиотеками. То есть если вы раньше работали с Hibernate или Rest Assured, то не нужно переучиваться на работу с чем‑то неизвестным и не совсем нужным.
В‑третьих, подробное логирование и Allure‑отчеты делают процесс автоматизированного тестирования максимально простым и удобным.
Все эти доработки помогают нам сократить время на тестирование и сосредоточить свои усилия на более сложных кейсах, которые мы считаем нецелесообразным автоматизировать.













Написать комментарий